
こんにちは!GIMLE チームで MLOps サービスを担当している木村です。
2018 年以来 4 年ぶりにラスベガスの地に再度降り立つことが出来ました!
今回の re:Invent では ML 関連のセッションを中心に参加していきます。
1 日目は「Evolution of the machine learning development environment」というチョークトークに参加しました。 セッションの内容と、それを聞いてからの自分なりの考えを書いてみます。

機械学習の市場の広がり
昨今、日本でも AI や機械学習に関する話題を耳にすることが増えました。 これは世界規模で見ても同じく、今後ますます AI が活躍することが予想されています。 アメリカの調査会社は、次のように述べています。
- By 2025, global spending on artificial intelligence (AI) will reach $204 billion - IDC
- By the end of 2024, 75% of enterprises will shift from piloting to operationalizing AI - Gartner
- 57% said that AI would tranform their organization in the next tree years - Deloitte
各調査会社から、本格的な AI 運用の開始により、市場規模は拡大し、さらに AI が組織を変革するという予想が発表されています。 一方で、こんな内容もあります。
- Only 53% of projecs make it from AI prototypes to production - Gartner
試験版からプロダクトに至るプロジェクトはたったの 53% だと言われています。 なぜこのようなことが起こるのでしょうか?
機械学習をうまく運用できる環境がカギとなる
機械学習を利用したプロダクトの開発と運用のやり方に問題があるのではないかと考えられています。
実際に、データを使って学習モデルを作成し、プロダクトに組み込んだものを運用する流れをものすごく大まかに考えると、下記の流れになります。
- データの分析
- データを用いて学習モデルの作成
- アプリケーションの開発
- 学習モデルをアプリケーションへ組み込み
- アプリケーションの運用
機械学習を組み込んでいない従来のアプリケーションをリリース後、どのような作業を実施しているか想像してみてください。ユーザーの声に耳を傾けながら、バグの修正や追加機能の実装などをすることが多いかと思います。
機械学習を組み込んだアプリケーションでも同様に、上記の流れを実施した後、アプリケーションと学習モデルの改良が発生します。特に機械学習を利用して結果を得ている場合、学習モデルの精度向上がとても重要になってきます。
学習モデルの精度向上を行う場面で実施することと言えば、データの見直し、特徴量検出、学習アルゴリズムのパラメータ調整など、多岐にわたります。
それぞれの作業で専門性が高く、分担して行われることもありますが、この作業を素早く実施しながら学習モデルの精度を向上させていくことが求められます。
学習モデルの精度向上に向けた調査後、アプリケーションへの組み込みまでを手作業で実施するとなると、時間がかかることが容易に想像できます。
また、実際の運用場面を考えると、学習モデルをスケーリングさせる運用や、機械学習環境用の CI/CD についても考えなければなりません。
これらの作業を円滑にできるようにすることが、機械学習を利用したアプリケーション開発ではとても重要になります。
では、これら複数の課題を解決し、機械学習 (ML) を利用したアプリケーションを運用 (Ops) するにはどのようにすればよいでしょうか。
MLOps を熟成させる
MLOps の実施にあたり、下記キーワードが紹介されました。
- Flexibility: 柔軟性
- あらゆるフレームワークに対応できること
- Reproducibility: 再現性
- 過去の機械学習を再現できること
- Reusability: 再利用性
- 機械学習のコンポーネントを再利用できること
- Scalability: スケーラビリティ
- オンデマンドでリソースをスケーリングできること
- Auditability:監査可能性
- ログやバージョン管理、アーティファクトの依存関係を管理できること
- Consistency: 一貫性
- 環境間の差異を最小限に抑えること
これらを取り入れながら、快適な MLOps 環境を構築します。
実際にどのようなインフラを構築すればよい?
本セッションのテーマとして、アプリケーションを製品として展開することを前提に、機械学習用アカウントと、アプリケーションの開発用、ステージング用、本場用アカウントの計 4 環境の構築について考える時間がありました。
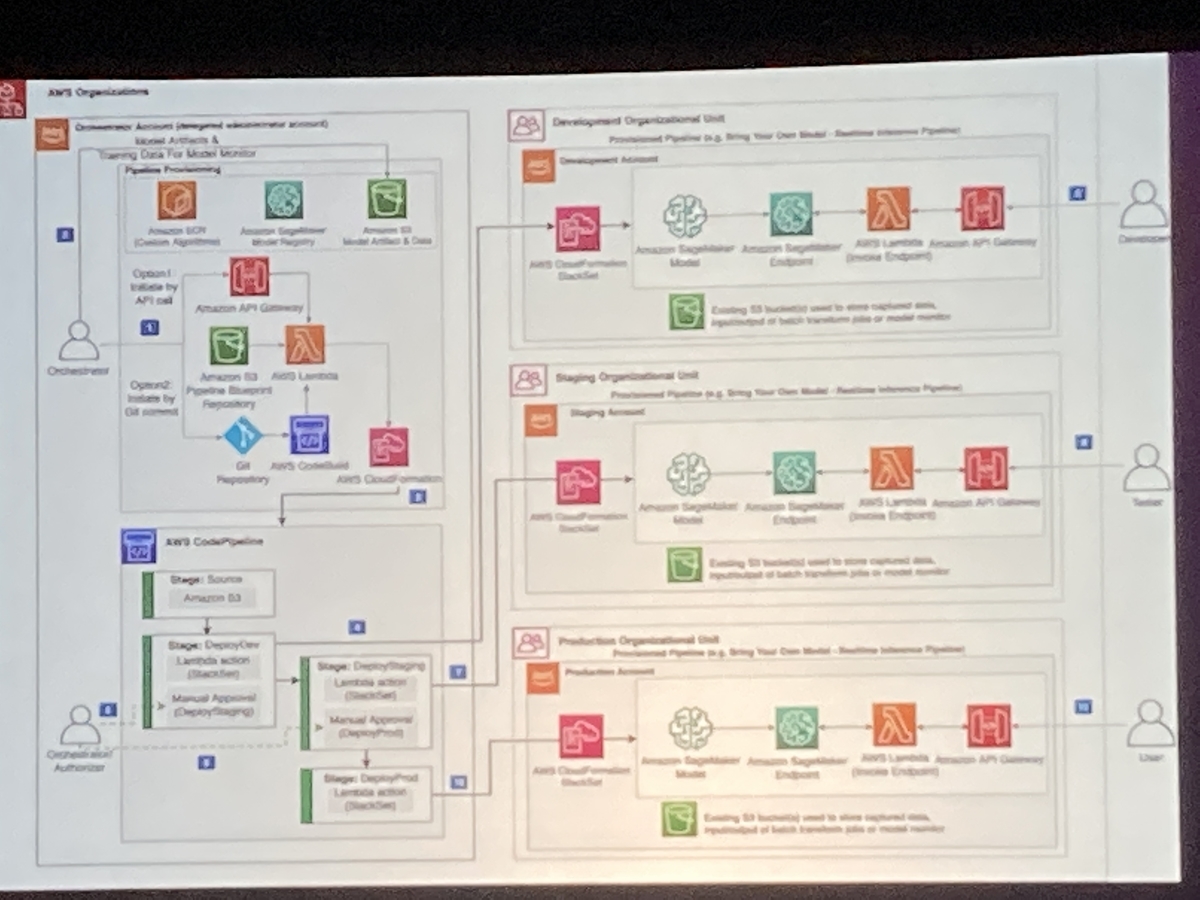
まずは機械学習用アカウントの環境を構築するところから始めます。画像の左上部分にあたりますが、SageMaker Studio や S3 を使いながら、データ分析や機械学習の作業を実施する環境を作ります。この環境は主にデータ分析や学習モデルを作成する機械学習エンジニアが作業をする環境となります。
ある程度コードを書きながら学習モデルが作れるようになったあたりで、繰り返し利用するためのコードの標準化とデプロイの標準化をしていきます。SageMaker Pipeline を活用しながら、データ変更やパラメータ変更に強い環境を作ります。
繰り返して学習モデルが作成できる環境が整ったら、モニタリングとアプリケーション用のアカウントへのデプロイについて考えます。画像の左下部分にあたりますが、機械学習用アカウントで作成した学習モデルをそれぞれのアカウントにデプロイできるよう、Code シリーズを利用しながらさらに環境を構築していきます。
最終的に、開発、ステージング、本番環境へデプロイしたり、今後他の製品に展開できるようにしていきます。画像の右半分にあたります。これら全体を CloudFormation でテンプレート化しておくとよいでしょう。
機械学習に関わるエンジニア専用の機械学習用アカウントを作成しつつ、アプリケーションを別のアカウントで用意しておき、学習モデルを機械学習用アカウントからアプリケーション用アカウントにデプロイすることで、それぞれの役割に沿って分けた環境が構築ができています。アカウントごとのロール管理などがしやすいのではないかと思います。
でも実際あまりポピュラーではないのはなぜ?
本セッションの 2 つ目のテーマです。アメリカでもあまりポピュラーではないようですが、それはなぜでしょうか?
私がお客様とお話をする際に、機械学習の利用状況を伺う場面がありますが、ローカルで実施されていたり、 SageMaker を使って機械学習に取り組んでいるがそれで終わっていたりと、運用までは実施されていないお客様が多いように感じます。アメリカでも試験版からプロダクトになるプロジェクトが 53% となる理由もきっと同じではないかと感じました。
これは私の考えになりますが、MLOps がポピュラーではないのは、機械学習エンジニアの作業範囲にクラウドやアプリケーション開発に関する知識を要さないところにあると感じています。
例えば、ウェブアプリの開発者を考えてみると、アプリケーションの開発と配信について考えながら作業を進めるかと思います。配信部分について考える際、少なくともサーバーの存在を理解しながら開発を進める必要があり、サーバーやクラウドをツールとして扱う場面が出てきます。
一方で機械学習はというと、データとローカル端末があれば作業ができてしまいます。そもそも興味がデータ分析というところにあるため、ローカル端末を計算機として扱い、結果が得られるとそれで満足できてしまいます。
これは作業手法についても現れているように思います。 私が 10 年ぶりに機械学習について取り組み始めた際、10 年前と作業手法が大きく変わっていない点にとても驚きました。それぐらい作業手法が変わっていないのは、結果が得られさえすれば満足できるからかもしれません。
MLOps のサイクルを回していくとき、機械学習エンジニア、アプリ開発エンジニア、クラウドエンジニアと、登場人物がたくさん出てきます。しかしそれぞれの登場人物の統率がとれていないということが発生したり、機械学習エンジニアがどういう作業が必要なのかを汲み取ったクラウド環境を準備できていなかったりするのではないでしょうか。それぞれのエンジニアがそれぞれの領域に興味を示し、理解し合う必要があると感じています。
弊社からお客様に対し、より良い MLOps の体験をお届けできるように、日々取り組んでいきたいと感じました。
