この記事はJapan AWS Top Engineers Advent Calendar 2024の5日目の記事です。
こんにちは、AWS re:Invent 2024 に現地参加していた森井です。
「Deep dive into Amazon Aurora DSQL and its architecture」というセッションに参加してきましたので、今回はその概要をご紹介します。 新発表サービスの情報にいち早くアクセスできるのは、re:Inventに現地参加する醍醐味ですね。
アーカイブが公開されているので、より詳細に知りたい方はこちらをご覧ください。 本記事のスクリーンショットはすべてこの動画からの引用です。
Aurora DSQLとは何か?
まず冒頭で、Aurora DSQLには以下の特性があると紹介がありました。
- トランザクションに最適化されたリレーショナルデータベース
- スケーラブル
- サーバーレス
- Active-active構成
- マルチリージョン
- PostgreSQL互換
このあたりは基調講演でも触れられていたので、ご存じの方が多いかもしれません。
Acitve-activeで水平スケールするリレーショナルデータベース技術は今までもありましたが、これがサーバーレスサービスとしてAWSに登場したことに可能性を感じます。 ミッションクリティカルなシステムだけでなく、小規模なシステムでも運用が楽で信頼性の高いデータベースとして採用できるかもしれません。
トランザクションデータベースの再考
Aurora DSQLは去年の基調講演で紹介された「The log is database」という考え方の流れを汲んでいます。

ログこそがデータベースであるため、ログを書き込むことで原子性と耐久性を実現できます。 このログサービスはジャーナルと呼ばれ、S3やKinesisやDynamoDBなどのサービスにも使われています。
「The log is database」を引用していることから、Aurora DSQLがAuroraの発明を引き継いだデータベースであることがわかりますね。この考え方についての詳しい解説は、kumagiさんのAmazon Auroraの先進性を誰も解説してくれないから解説する #AWS - Qiitaをぜひご覧ください。
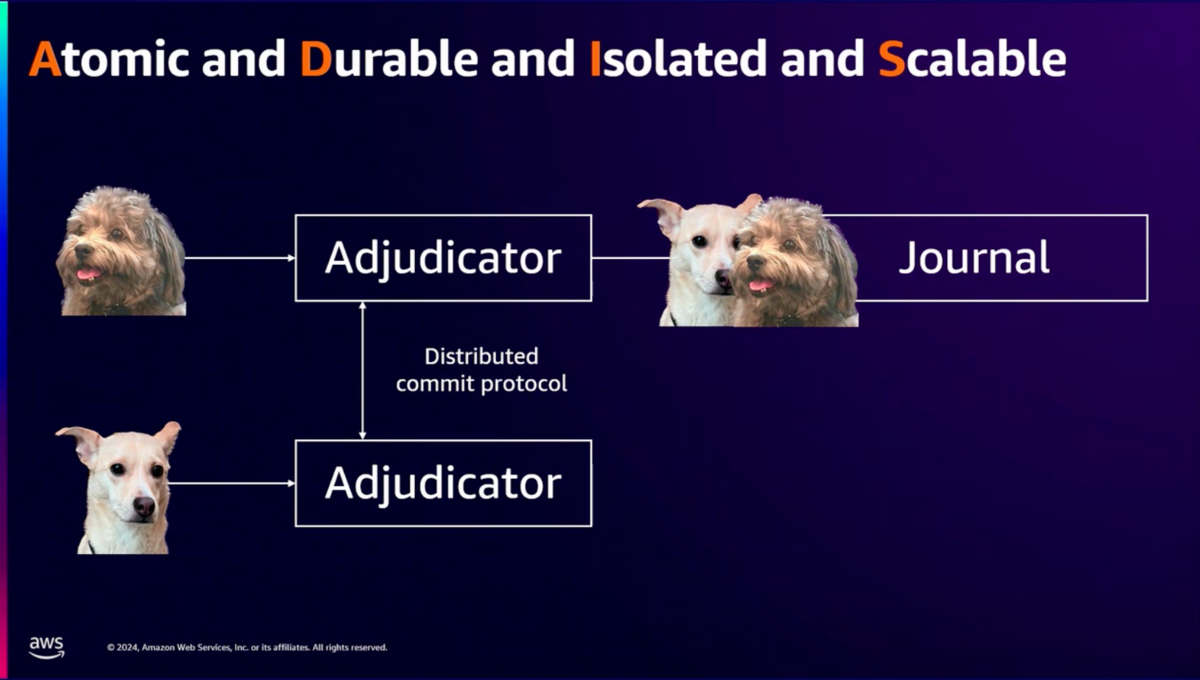
同じ行への変更による競合を避けるために分離システムとして、Adjudicator(裁定者)を導入し、Adjudicatorをスケーラブルにするために、分散コミットプロトコル(2相コミットの変形)を導入しています。
2相コミットは、複数ノードにまたがるトランザクションの原子性を実現するためのアルゴリズム*1です。 最初のフェーズで準備リクエストを送り、コミットできるのかを各ノードに問い合わせ、合意が返ってきたら次のフェーズでコミットに進む方式を取ります。
ストレージはデータをクエリを担当しますが、耐久性や並行性制御に責任を持ちません。 ストレージ層にクエリ処理を押し込むことにより、RTT(Round Trip Time)を大幅に減らすことができます。

クエリプロセッサーはFirecrackerで実行しています。 FirecrackerはLambdaで使用されているVM技術で、セキュアで起動が早いことが特徴です。
衛星クロックで同期したタイムスタンプによるMVCC(Multiversion Concurrency Control)を使用しています。 読み取りは特定のスナップショットを参照すれば良いだけです。 ストレージノード間で通信する必要はありませんし、ロックを取得する必要もありません。

読み取りはクエリプロセッサーからストレージに直接読むため分離と実装が簡単になっています。
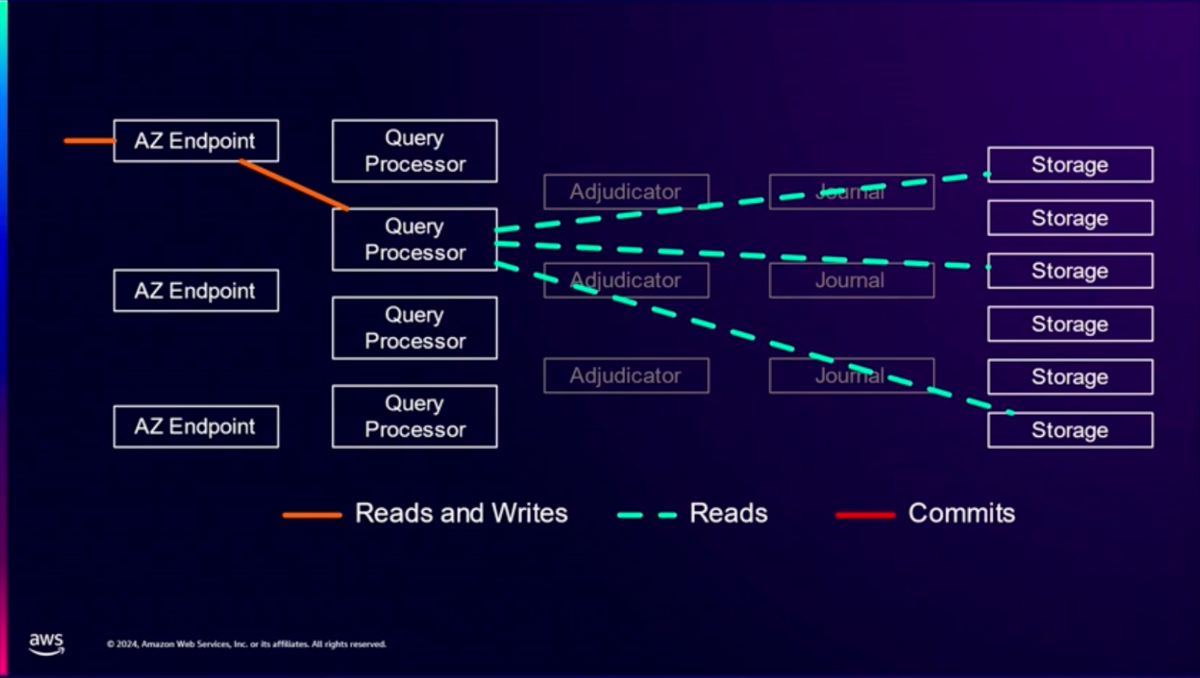
書き込みはAdjudicatorのチェックを通してジャーナルに書き込まれ、ストレージに反映されます。
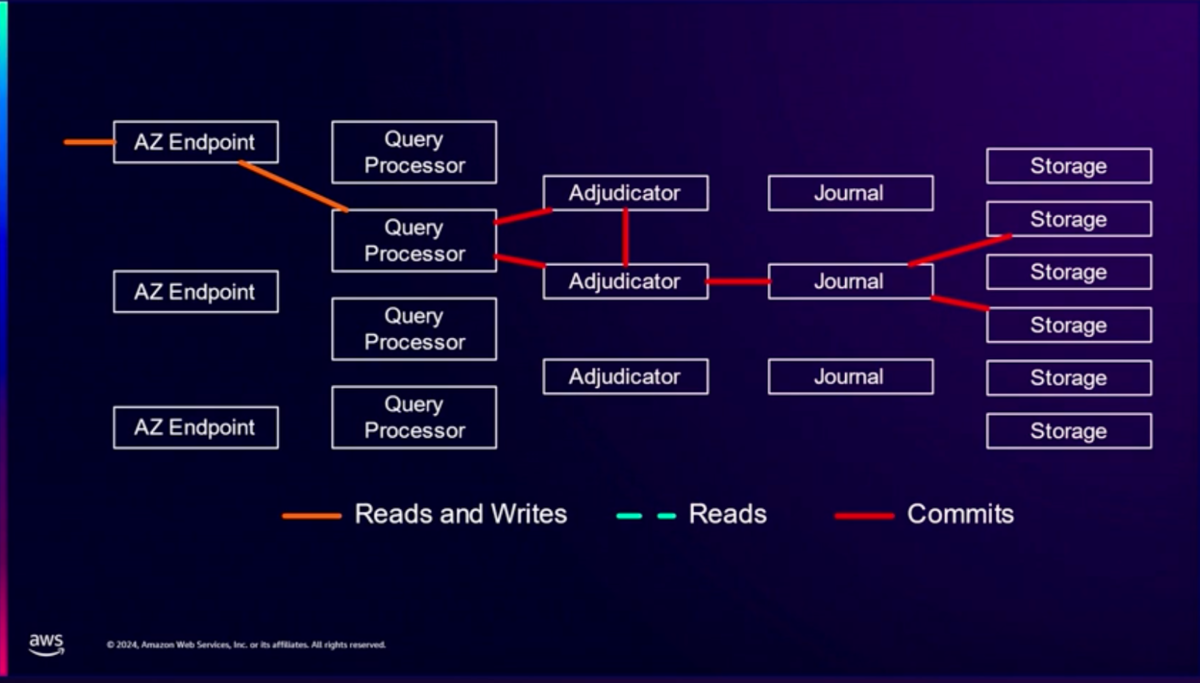
クエリプロセッサーを分離するアーキテクチャーは TiDB Serverlessのアーキテクチャとも似ています。比較してみると面白いかもしれません。*2
分離方式
スナップショット分離レベルが採用されています。 シリアライザブルレベルは利点がありますがコストもかかるため、スナップショット分離がスイートスポットだそうです。 通常のPostgreSQLではトランザクション分離レベルをユーザが選択できますが、Aurora DSQLではスナップショット分離レベルのみに制限されるようです。

読み取り時にT startというタイムスタンプを生成し、コミット時にT commitというタイムスタンプを生成します。 T startとT commitの間の時間に他のトランザクションが同じキーに書き込みをしていない場合のみ、トランザクションをコミットできます。これによりトランザクションの分離を実現しています。

分離方式についてはSpannerと似た仕組みになっているようです。 高精度の時計が使えるクラウドならではですね。
クロスリージョン
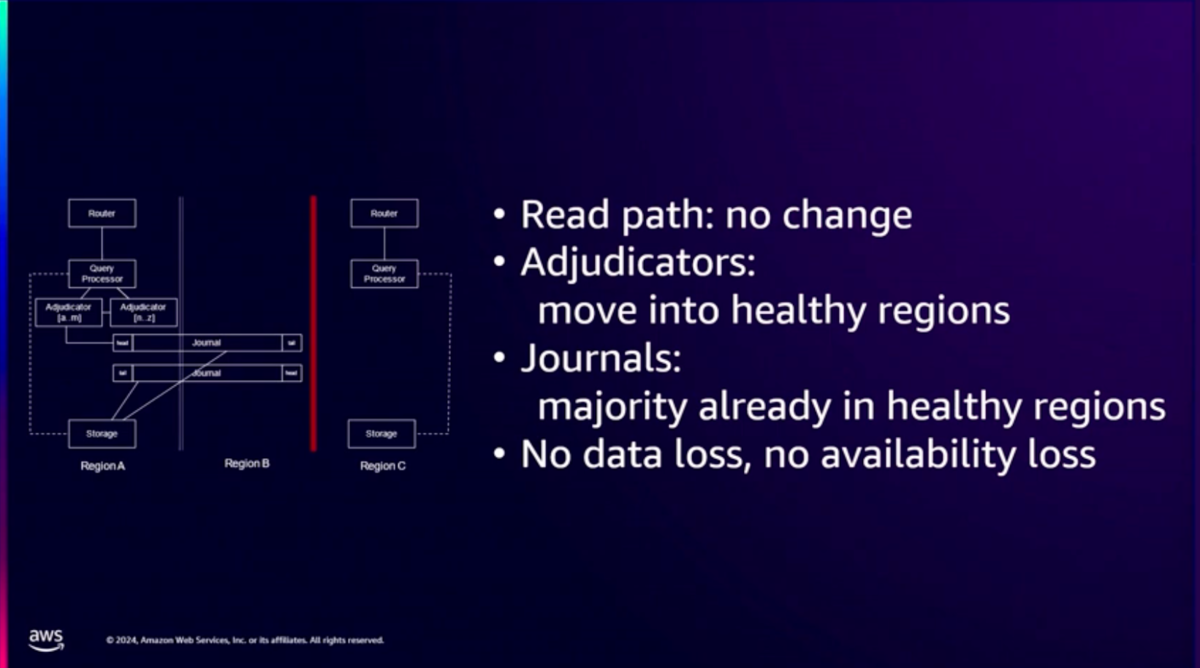
AWSは光ファイバー網を整備しているので高速なネットワークが使用できますが、それでもリージョンを跨ぐと時間がかかるためRTTを最適化することが大事です。 Aurora DSQLではコミット以外の命令はローカルに実行されるように設計されているため、リージョンを跨がない設計になっっています。

Aurora DSQLはフェイルオーバーが早くなることに最適化されています。 リージョン障害が起きても読み取りの流れは変わらず、データロスもなく、可用性にも影響がありません。
実装の品質
プログラミング言語にはRustを使用しています。 パフォーマンスが高くメモリ安全性変えられることが採用理由だそうです。
決定論的シミュレーションテスト(Deterministic simulation testing)を実施しています。 これは、ネットワークが不安定でクロックが信頼できない時のシミュレーションなどをビルド時に行うものです。 tokio-rs/turmoilを使用しているとのことです。
ファジングも活用し、何十億ものトランザクションを実行でPostgreSQLとの互換性をチェックしたそうです。 ツールの一部はOSSとして公開する予定だそうです。
形式手法も活用し、TLA+やPのようなツールで、設計したプロトコルをレビューし実装できていることを確かめたそうです。
実装の正しさと仕様の間のギャップを埋めるためにランタイム監視という技術を活用したそうです。アプリケーションログと正式な仕様を比較してチェックしたとのこと。
Rustで形式手法してファジングして…と流石はAWSさんと言いたくなる技術選定ですね。 今までのサービス開発の経験を大いに活かしている感じがしますね。 発表者のMarcさんはLambdaやEBS、EC2などの複数のサービスに関わり、形式手法を含む多くの功績を残されています。
まとめ
このセッションを聞いて、Aurora DSQLは非常に巧妙な設計で作られていることがわかりました。 Auroraにおけるストレージとコンピューティングの分離、Firecrackerによる仮想化などのAWSが今まで培った技術と、データベース領域の最新技術が高度に融合したアーキテクチャを、形式手法などの品質を支える技術の積み重ねが実現したサービスと言えるでしょう。
AWSはPurpose-built databasesという考え方を推進しており、目的別に最適なデータベースを提供することを目指しています。 Aurora DSQLが既存のデータベースサービスが満たせなかった目的を達成できるのか、今後も目が離せません。
*1:参考:Two-phase commit protocol - Wikipedia
*2:実はTiDBのCTOであるEd Huangさんがこのことに言及していますhttps://x.com/dxhuang/status/1864381005643305184?s=12