こんにちは!インフラ担当の木村奈美です。
前編 ではMackerelの基本的な導入手順についてご紹介しました。 後編では、プロジェクトの要件に合わせた、プラグインを利用した応用的な監視についてご紹介します。
プロセス数を監視する
今回の対象のプロジェクトでは、Mackerelデフォルトの収集項目に加えて、プロセス数も監視する必要があります。
Mackerelではプラグインによってプロセス監視が可能となります。 公式サイトの チェック監視に公式チェックプラグイン集を使う に沿ってプラグインを導入していきます。
チェックプラグインのインストール
インストールコマンドを実行します。
yum install mackerel-check-plugins
設定ファイル編集
前編で編集した設定ファイル /etc/mackerel-agent/mackerel-agent.conf に、チェックプラグインの設定を追記します。
書式は公式サイトの プロセス監視をおこなう を参照します。
今回の監視対象は7種類のプロセスです。それぞれのプロセスについて、閾値を定義します。
# 設定ファイルに以下を追記 [plugin.checks.check_sshd] command = ["check-procs", "--pattern", "sshd", "--critical-under", "1"] [plugin.checks.check_crond] command = ["check-procs", "--pattern", "crond", "--critical-under", "1"] [plugin.checks.check_chronyd] command = ["check-procs", "--pattern", "chronyd", "--critical-under", "1"] [plugin.checks.check_rsyslogd] command = ["check-procs", "--pattern", "rsyslogd", "--critical-under", "1"] [plugin.checks.check_nginx_master] command = ["check-procs", "--pattern", "nginx", "--user", "root", "--critical-under", "1"] [plugin.checks.check_nginx_worker] command = ["check-procs", "--pattern", "nginx", "--user", "nginx", "--critical-under", "2"] [plugin.checks.check_td-agent] command = ["check-procs", "--pattern", "td-agent", "--critical-under", "1"]
今回は閾値として --critical-under (設定値を下回ったらCritical)の1つしか設定していませんが、複数指定することも可能です。
指定可能な閾値のオプションを公式サイトより引用します。
- -w, --warn-over
- 設定値を上回ったらwarning
- -c, --critical-over
- 設定値を上回ったらcritical
- -W, --warn-under
- 設定値を下回ったらwarning
- -C, --critical-under
- 設定値を下回ったらcritical
Mackerelエージェントの再読み込み
Mackerelエージェントを再読み込みして、設定を反映します。
systemctl reload mackerel-agent.service
監視状況を確認してみる
ホスト画面にて、プロセス監視状況を確認できるようになりました。
スクリーンショットは見切れて4つのプロセスしか表示されていませんが、実際には設定ファイルで設定したもの全てが表示されています。
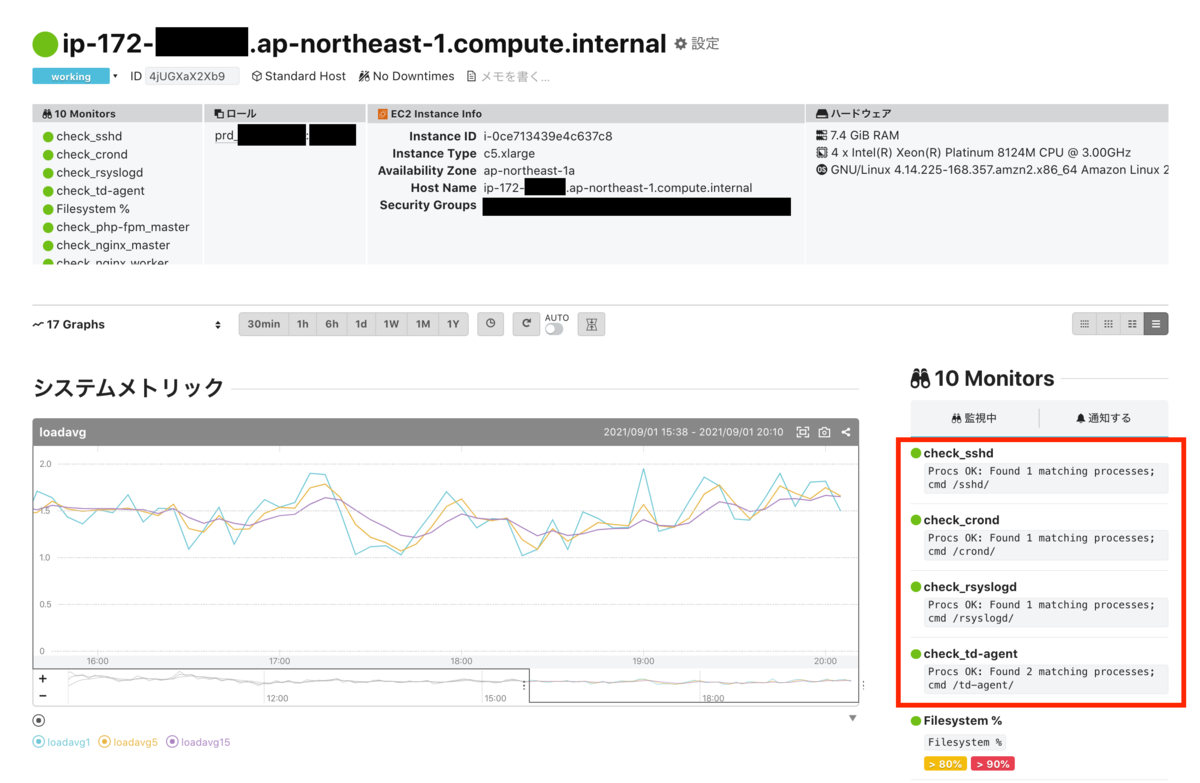
チェックプラグインを利用した監視は、設定ファイルに記述した条件が監視ルールとなるため、改めて監視ルールを作成する必要はありません。 以上でプロセス監視の設定は完了です。
閾値を超過すると通知が飛んできます。 以下は Slack 通知の例です。

Webサーバーのエラー率を監視する
次は別のプラグインを使った監視の紹介です。 プロジェクトの障害対応を容易にするため、Webサーバーのエラー率を監視します。
ある時期、監視対象のインスタンス群の中で「特定のインスタンスのみHTTP 5xxエラー率が上昇する」という障害が頻発するようになりました。 一度エラー率が上昇すると継続するため、初動としては、ユーザーからそれ以上アクセスされないように問題のインスタンスをALBから切り離す対応をとっていました。 もともと全体的なエラー件数の監視はしていたものの、どのインスタンスで問題が起きているかまでは分かりません。そのため、人の手で問題のインスタンスを特定する必要がありました。 そうしている間にもエラーは続くため、非常に焦ります。
なんとかして問題のインスタンスを素早く特定して切り離しできないか、ということでMackerelを活用することにしました。
Mackerelでは、デフォルトのメトリックに加え、ミドルウェアのメトリックを収集するためのプラグインが用意されています。 そのうちの1つである mackerel-plugin-accesslog を使えば、アクセスログを元に、ホストごとのHTTPステータスコードの割合を収集できます。 さらに、前編でも紹介したホストメトリック監視を設定することで、「特定のロールに1台だけエラー率の高いホストがいる」ということを検知できます。
公式サイトの ミドルウェアのメトリック可視化に公式プラグイン集を使う に沿ってプラグインを導入していきます。
プラグインのインストール
インストールコマンドを実行します。上で紹介したチェックプラグインとは異なるためご注意ください。
yum install mackerel-agent-plugins
設定ファイル編集
さきほども編集した設定ファイル /etc/mackerel-agent/mackerel-agent.conf に、アクセスログの設定を追記します。
書式はプラグインの README を参考にします。
# Nginx accesslog [plugin.metrics.accesslog] command = "/usr/bin/mackerel-plugin-accesslog /var/log/nginx/access.log"
Mackerelエージェントの再読み込み
Mackerelエージェントを再読み込みして、設定を反映します。
systemctl reload mackerel-agent.service
メトリックを確認してみる
それでは、メトリックがどのように収集されているか確認してみましょう。
サービスのページでは、 custom.accesslog.* というメトリックを選択できるようになっています。ここでは特定のサービスとロールに属するインスタンスの状況を一括で確認できます。

ホスト詳細のページでは、4種のステータスコードの割合を確認できます。
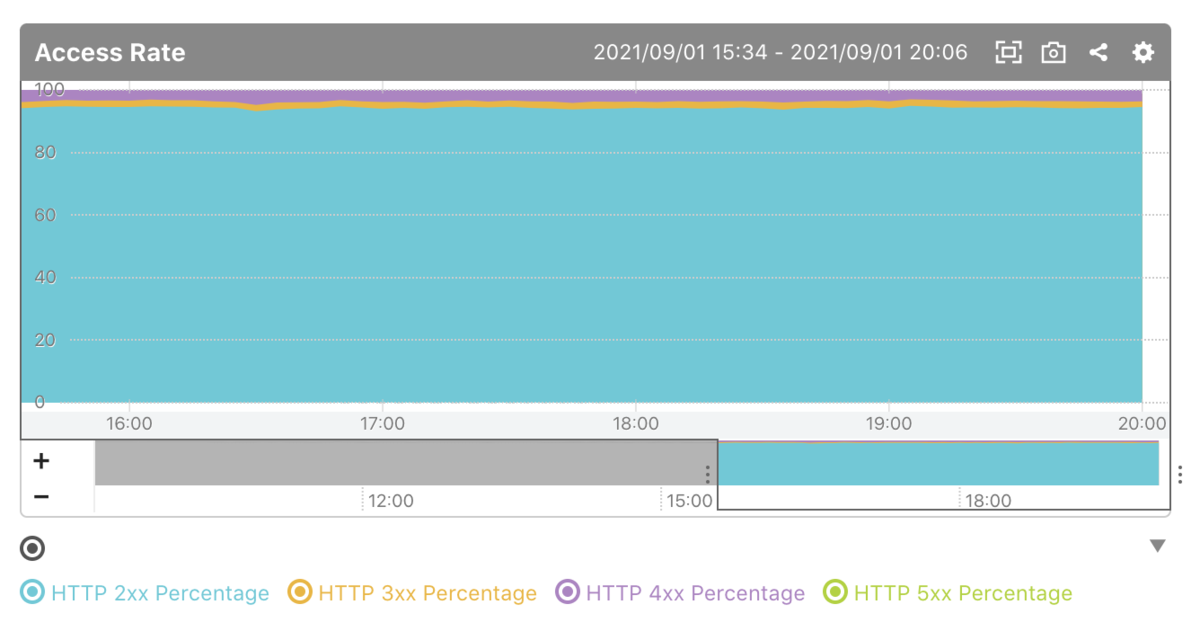
監視ルール作成
5xxエラー率が一定割合を超えると通知するよう、監視ルールを作成します。
監視対象のメトリックとして custom.accesslog.access_rate.5xx_percentage を選択します。
閾値は、5xxエラー率が1%を超えるとWarning、5%を超えるとCriticalとなるよう設定しました。

これで、特定のインスタンスでエラー率が上昇した際に通知が来るようになりました! 以下はSlack通知の例です。
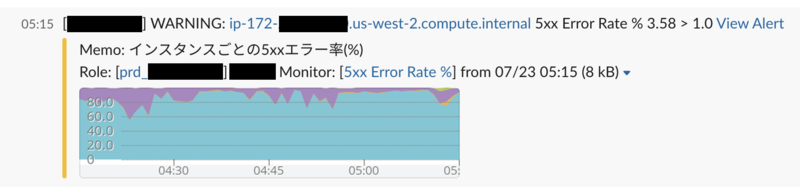
「どのインスタンスで問題が起きているか」が通知から分かるため、問題のインスタンスをすみやかに切り離し、調査できるようになりました。
自動化の検討
ここまでの手順では、障害発生時のALBからのインスタンス切り離しは依然として手動で行う必要があります。 今回は対応しませんでしたが、AWS EventBridgeと通知を連携させれば、インスタンス切り離しまで自動化できるのではと考えています。 機会があれば、次のステップとしてぜひトライしてみたいです。
(余談)サポートに問い合わせてみた
ここまでの監視設定をするにあたり、ひとつ気になる点がありました。 ホストメトリック監視の説明に、以下のような記載があります。

ホストのメトリックの平均値を監視します。
この文言を見て、筆者は疑問に思いました。
「『平均値』とはどういうことだろう? 監視対象のホスト間で平均をとるということだろうか?だとすれば、ロールの中で1台だけ不調なホストがあっても、平均化されて分からなくなってしまうのでは?」
そこで、この「平均値」の意味をサポートに問い合わせてみました。 すると、1日と経たずに回答が返ってきました。
どうやら懸念していたようなホスト間の平均値ではなく、単一ホストのメトリックのうち何点か(この点数はホストメトリック監視設定の「平均値監視」で調整可能)の平均値を監視する、という意味とのことでした。 閾値を超えたかどうかはホスト毎に評価されるため、目的の「問題のインスタンスの特定」が実現できると分かって安堵しました。 おかげでお客様に自信を持って説明できたので、聞いておけてよかったです。
サポートがしっかりしていて安心して使えることも、使いやすい要因の1つであると感じます。 ご対応いただいたサポート担当の方、ありがとうございました。
おわりに
2回にわたってMackerelをご紹介しました。 もしご興味をお持ちの方がおられましたら、2週間のトライアルや、無料プラン(一部機能に制限あり)が利用できますので、ぜひご検討ください。
https://ja.mackerel.io/pricing
みなさまのサーバー監視がよりよいものになることを願っています。