記事更新:
2022/8/19 目次を追加
2022/8/25 MLOps への道 記事一覧を追加
こんにちは! GIMLEチームの太田です。
突然ですが、私、8/7に行われる JAWS-UG京都 にて発表することになりました!
イベントのテーマはズバリ「本気のAI」
今までなんとなくAI・機械学習という言葉は知っていましたが、実践したことはありませんでした。
これを機会に本格的にAI・機会学習というテーマに取り組んでいこうと、少しずつ実践している次第です。
そのアウトプットの一環として、今回から数回に渡り、AI初心者の私がAmazon SageMakerでMLOps (機械学習オペレーション) に取り組んだ内容を投稿していこうと思います。
※本シリーズは「できるだけシンプルに」「End To Endで」継続的学習・デプロイ基盤の作成に至るまでの過程を実践してみよう、という想いのもとで執筆しております。扱うデータの内容や学習アルゴリズムの詳細、推論結果の解釈の仕方など、機械学習のディープな部分にはあまり踏み込まない予定ですので、ご留意いただければ幸いです
- はじめに
- 検証した環境
- 前提となる知識・用語
- 1. データを準備する① 元データを取得して、SageMaker Studioで使えるようにする
- 2. データを準備する② SageMaker Studioでのデータ準備
- 3. 学習用アルゴリズムにデータを投入して、学習させる
- 4. 推論用のエンドポイントを作って、予測してみる
- 5. お片付け
- おわりに
- 参考情報リンクまとめ
- MLOps への道 記事一覧
はじめに
第一回目となる今回は、線形学習アルゴリズム(線形回帰)を使用して、
年度ごとの平均給与額データから未来の平均給与額を予測するモデル作成を実践してみました。
大まかな流れとしては、以下のようになります。
- データを準備する① 元データを取得して、SageMaker Studioで使えるようにする
- データを準備する② SageMaker Studioでのデータ準備
- 学習用アルゴリズム(今回は線形回帰)にデータを投入して、学習させる
- 推論用のエンドポイントを作って、予測してみる
- お片付け
では、早速いってみましょう!
検証した環境
- 端末:MacBook Pro
- OS:macOS Monterey 12.4
- CPU:Apple M1 Max
前提となる知識・用語
AWSに関すること
- 使用するAWSのサービス
- S3
- Athena
- SageMaker
- SageMaker Studio
- SageMaker Python SDK
AWSの一般的な知識や、コンソールを用いた操作方法の知識がある前提となります。
また、SageMaker Studioのセットアップ方法・起動方法については本記事では触れません。
必要に応じて、以下のようなドキュメントを参照いただければと思います。
AI・機械学習に関すること
- AI
- 機械学習(Machine Learning / ML)
- 機械学習オペレーション(Machine Learning Operations / MLOps)
- モデルの学習
- 学習済みモデルを使った推論
- 線形回帰
- 説明変数と目的変数
私はこれらの要素についての知見がなく、ゼロからのスタートでした…… 本記事を読むにあたっては、以下のようにイメージいただければよいかと思います。
- モデル
- 入力されたデータを解析して、評価や判定を行った結果を出力するもの
- データを入力/出力させて「学習」させることにより、解析の精度/出力の精度を高めていく
- 学習
- データを入力/出力させて、モデルの解析/出力精度を高めていくこと
- 推論
- 学習が済んだモデルにデータを入力/出力させること
- 説明変数
- 推測・予測を行うための値。学習・推論の際にモデルに入力する値
- 今回の場合は、「年度」と「平均給与額」
- 目的変数
- 推測・予測したい値。学習・推論の際にモデルから出力される値
- 今回の場合は、(未知の年度を入力した時の)「平均給与額」
プログラミング言語・その他
- 基本的なPythonコードの書き方
- 使用するPythonのライブラリ
- pandas
- pandas-profiling
- Docker・コンテナ技術
基本的なPythonコードの書き方については、知っている方が望ましいです。
また、データをpandasのデータフレームで扱うため、pandasについての知識もあると良いです。
コマンドの実行などはありませんが、Docker・コンテナ技術に関わる用語も少し出てきます。
1. データを準備する① 元データを取得して、SageMaker Studioで使えるようにする
1.1 データの取得と、CSVファイルの作成
まずは、分析するデータを取ってくるところから始めていきます。
今回は、政府統計の総合窓口(e-Stat) から、「民間給与実態統計調査」の結果を取ってきました。
(e-Statのトップページから「分野」を選択すると、「労働・賃金」のところに「民間給与実態統計調査」があります)
ここから、調査が行われた年度別のExcelファイルをダウンロードして、年間の平均給与額をCSV形式のファイルにまとめていきます。
実際に2020年の調査結果(第1表 給与所得者数・給与額・税額)をダウンロードしてみると、以下のような形式でした。
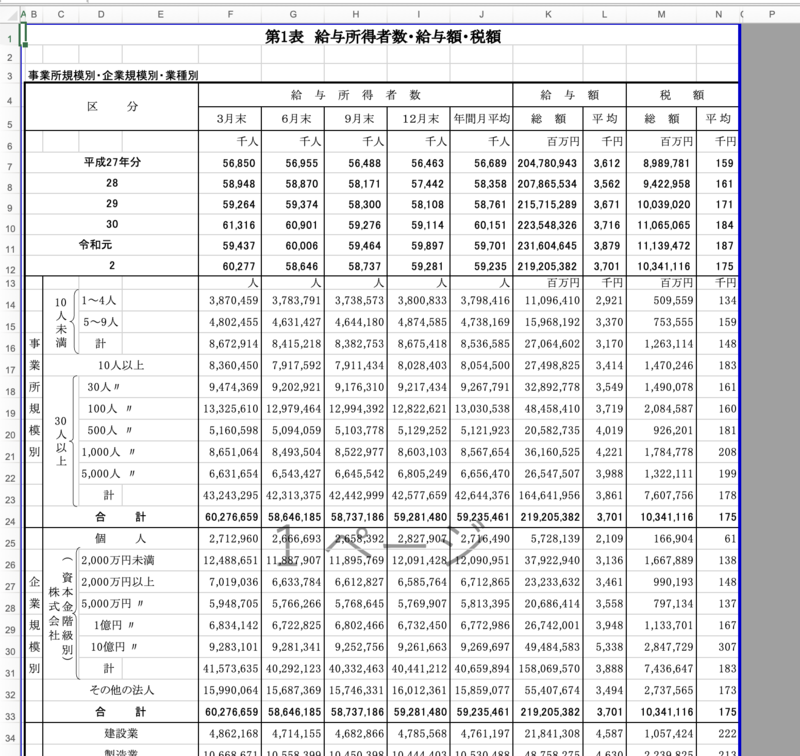
L列に過去6年分の平均給与額が載っているようなので、2020年 → 2014年 → 2008年... と、6年ずつ遡ってファイルをダウンロード。
test.csv というファイルを作ってCSV形式でまとめてみると、以下のようになりました。
year,value 1994,4078000 1995,4107000 1996,4118000 1997,4183000 1998,4185000 1999,4032000 2000,4082000 2001,4001000 2002,3887000 2003,3753000 2004,3766000 2005,3710000 2006,3670000 2007,3672000 2008,3652000 2009,3502000 2010,3547000 2011,3583000 2012,3521000 2013,3595000 2014,3614000 2015,3612000 2016,3562000 2017,3671000 2018,3716000 2019,3879000 2020,3701000
1列目に年度、2列目に年間平均給与額を記載しています。
これで、1994年〜2020年までの、民間企業の平均給与額のデータができました。
次は、このファイルをS3のバケットにアップロードして、Athenaでテーブルを作成していきます。
1.2 CSVファイルのS3へのアップロードと、Athenaでのテーブル作成
1.2.1 S3バケットに、CSVファイルをアップロード
作成したCSVファイル test.csv をS3バケットにアップロードします。
今回S3バケットは既に作成済みのものを使用。e_stat_go_jp_minkan_kyuyo というフォルダを新たに作成して、その中にアップしました。
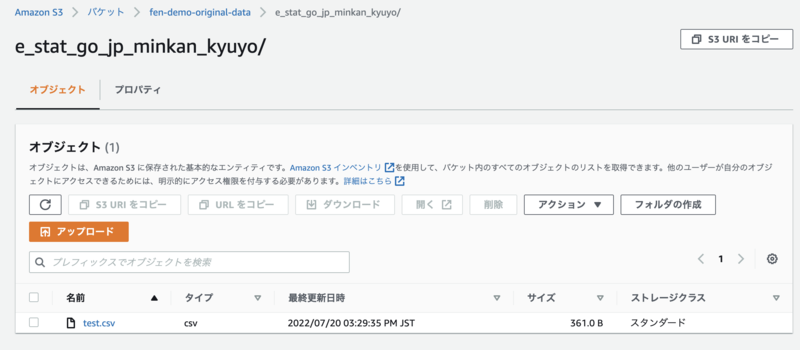
次に、Athenaを使ってデータベースとテーブルを作成していきます。
1.2.2 Athenaのクエリ結果の場所と暗号化の設定
まずは、Athenaのクエリ結果の場所と暗号化の設定を実施しておきます。
クエリエディタの「設定」タブにある、「管理」ボタンから設定します。
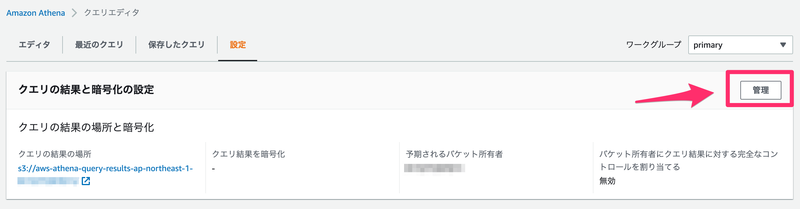
設定内容は以下のようにしました。
- クエリ結果の場所:クエリ結果を配置するS3バケットを指定
- 予期されるバケット所有者:S3バケットを作成したAWSアカウントIDを指定
- クエリ結果を暗号化:無効
- バケット所有者にクエリ結果に対する完全なコントロールを割り当てる:今回はクエリ結果の配置先バケットが同じAWSアカウントにあるので、チェックなし
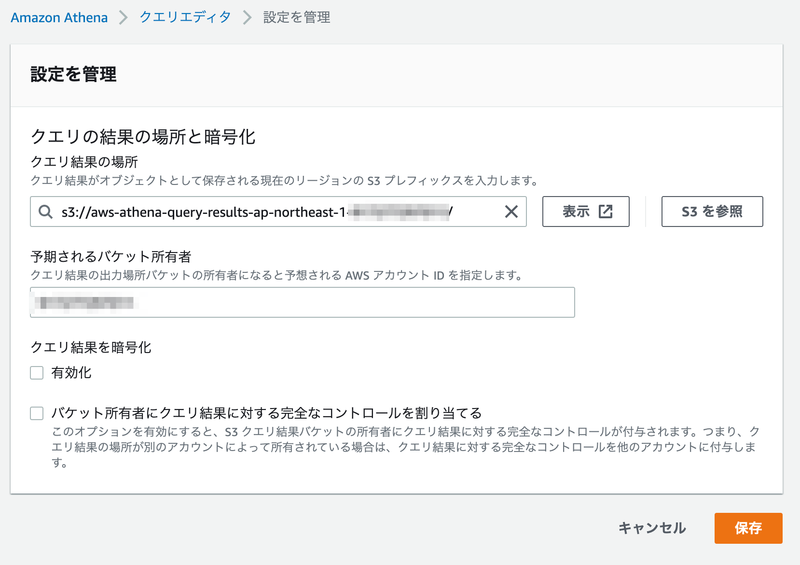
設定を保存して、次はデータベースとテーブルを作成していきます。
1.2.3 Athenaでデータベースとテーブルを作成
クエリエディタの「エディタ」タブ内、「テーブルとビュー」にある、「作成」ドロップダウンリストから「S3 バケットデータ」を選択して作成していきます。
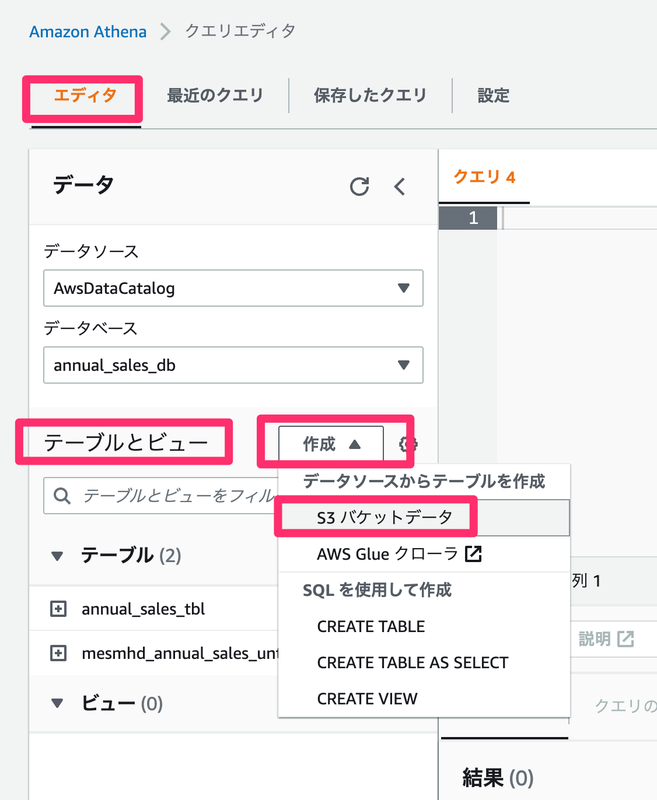
設定は、以下のようにしました。
- テーブルの詳細
- テーブル名:
e_stat_go_jp_minkan_kyuyo_table - 説明:省略
- テーブル名:
- データベース設定
- 既存のデータベースを選択するか、新しいデータベースを作成:データベースを作成
- データベース名:
e_stat_go_jp_minkan_kyuyo_db
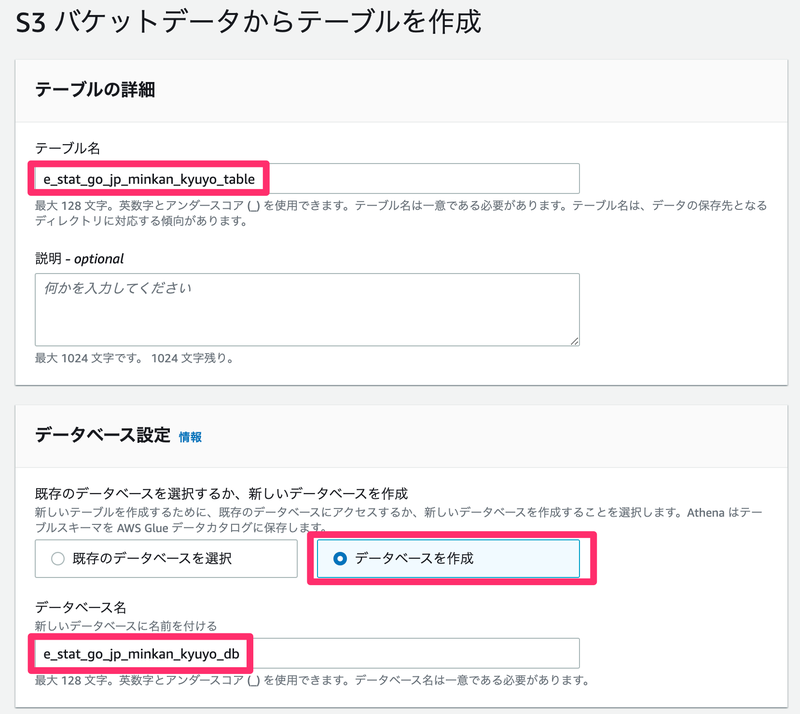
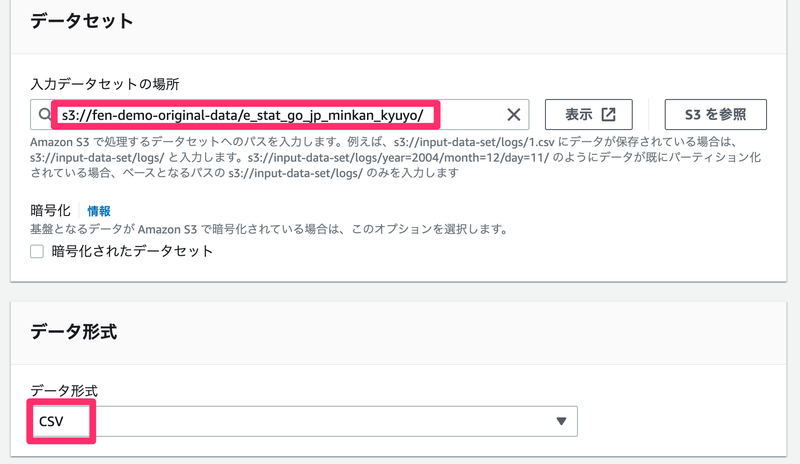
- データセット
- 入力データセットの場所:CSVファイルを配置したバケット/フォルダを指定
- 暗号化:チェックなし
- データ形式
- データ形式:CSVを選択
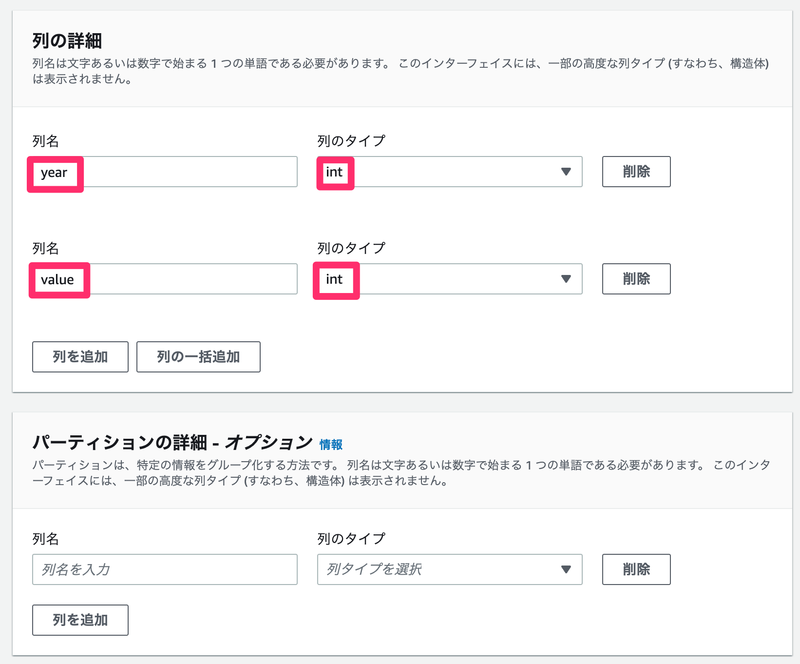
- 列の詳細
- 列名:
yearとvalue(CSV内の列の名前を指定) - 列のタイプ:両方とも
int(CSV内の列のタイプを指定)
- 列名:
- パーティションの詳細
- 今回はパーティションを作成しておらず、1つのファイルを置いているだけなので、入力なし
- テーブルクエリをプレビュー
- テーブル作成のためのクエリが表示されます
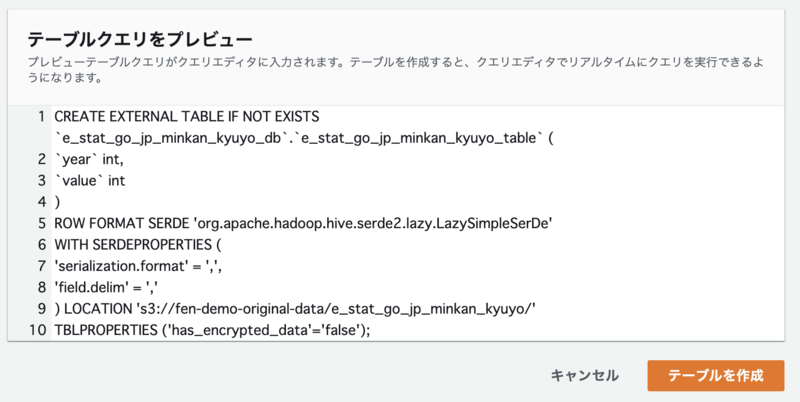
「テーブルを作成」ボタンを押すと、データベースとテーブルが作成されます。
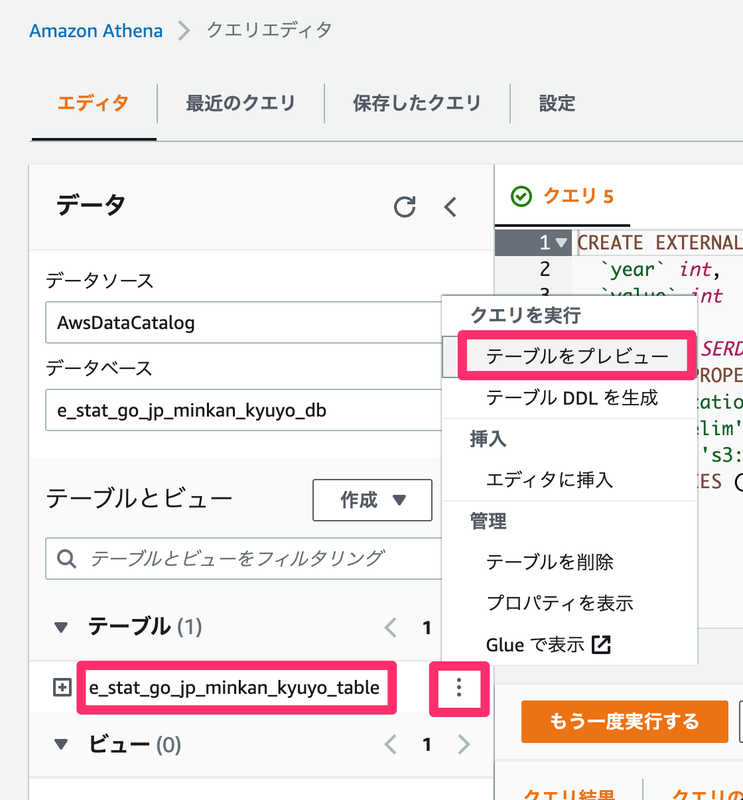
できたテーブルは、テーブル名の横にある三点リーダから、「テーブルをプレビュー」で確認できます。
テーブルのプレビュー結果:
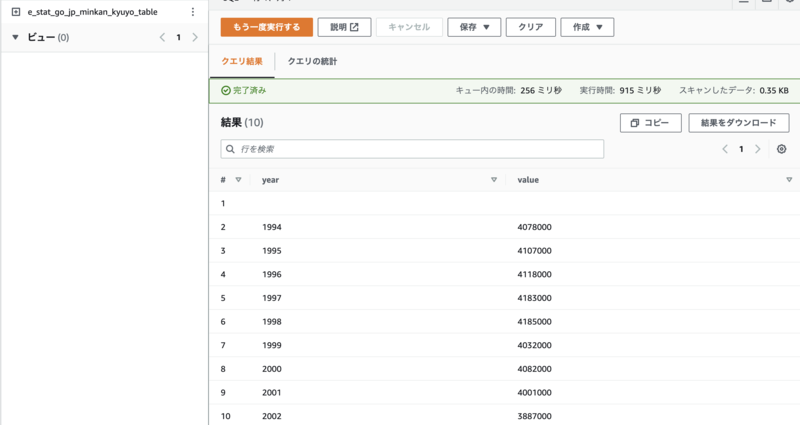
CSV1行目のヘッダーをスキップする設定を入れていないので、余分な行が入っています。
Athenaのテーブルプロパティで、ヘッダー行を無視するように設定するために、クエリエディタで以下のクエリを実行します。
ALTER TABLE <テーブル名> SET TBLPROPERTIES ('skip.header.line.count'='1');
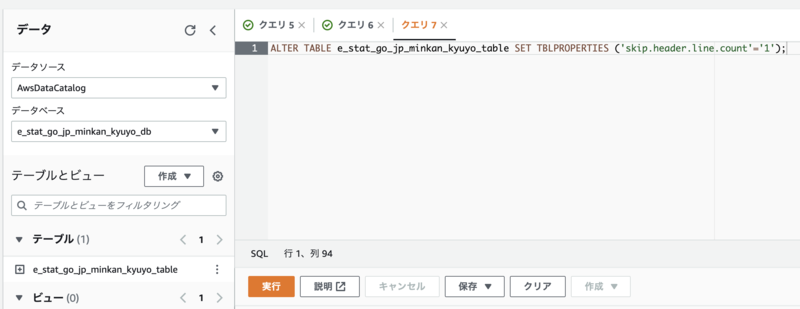
もう一度テーブルの内容を確認すると、余分な行が消えていることが確認できます。
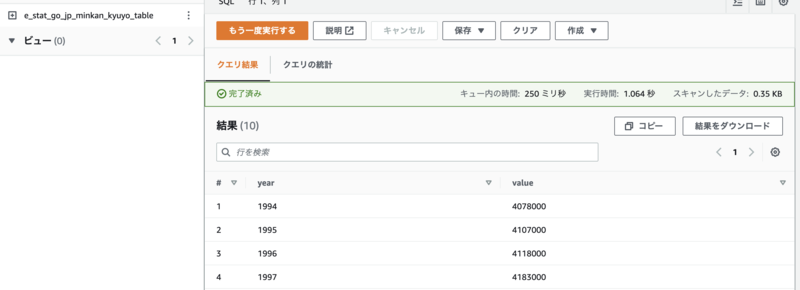
これで、S3バケットに置いたCSVファイルをAthenaのテーブルで見られるようになりました!
いよいよSageMaker Studioの出番です。
まずはデータを読み込んで準備するところから入っていきます。
2. データを準備する② SageMaker Studioでのデータ準備
ここからは、SageMaker Studioを使用した作業となります。
今回の実践は既にSageMaker Studioが使える状態でスタートしましたので、前提のところにも書いたのですが、セットアップ方法・起動方法については割愛させていただきます。
SageMaker Studioにて新しいノートブックファイルを作成して、コードを書きながら作業を進めていきます。
2.1 使用するライブラリのインストール
まずは、以下のコードを実行して PyAthena と pandas-profiling というPythonのライブラリをインストールします。
それぞれ、Athenaへの接続と取得したデータのプロファイルレポートを表示するのに使います。
import sys
!{sys.executable} -m pip install PyAthena pandas-profiling
実行結果(一部省略):
Successfully installed PyAthena-2.12.0 fonttools-4.34.4 htmlmin-0.1.12 imagehash-4.2.1 joblib-1.1.0 matplotlib-3.5.2 missingno-0.5.1 multimethod-1.8 pandas-1.3.5 pandas-profiling-3.2.0 phik-0.12.2 pydantic-1.9.1 scipy-1.7.3 seaborn-0.11.2 tangled-up-in-unicode-0.2.0 tqdm-4.64.0 visions-0.7.4
2.2 Athenaからのデータの取得と分割
次は、Athenaからデータを取得して、pandasのデータフレームに格納します。
この時に、以下の3つのデータに分けておきます。
- 学習用データ
- 検証用データ
- テスト用データ
学習用データはそのまんまの意味で、モデルに入力して「学習」してもらうためのデータです。
検証用データは、学習させたモデルの精度を確かめるためのデータです。学習の結果、どれだけ期待値に近い出力を出せているかを確かめるために使います。
テスト用データは、学習させたモデルの最終評価を行うためのデータです。ここでの結果が期待値と大きく異なるのであれば、モデルとしての精度は不十分であるという解釈になります。
また、今回はSageMakerの組み込みアルゴリズムである、線形学習アルゴリズム を使用しました。
こちらの入力データにCSVを使う場合は 目的変数を1列目に設定しておく必要がある とのことなので、データ取得時に列の順番を変更しています。
(ドキュメントより)
text/csv 入力タイプの場合、最初の列はラベルと見なされ、これが予測のターゲット変数です。
Athenaからのデータ取得と分割で使用するコードは以下のようになりました。
from pyathena import connect import pandas as pd # Athenaに接続 conn = connect( s3_staging_dir='s3://aws-athena-query-results-ap-northeast-1-XXXXXXXXXXXX/', region_name='ap-northeast-1' ) # 学習用データを取得・表示 query_train = 'select "value", "year" from "e_stat_go_jp_minkan_kyuyo_db"."e_stat_go_jp_minkan_kyuyo_table" where year < 2012;' df_train = pd.read_sql(query_train, conn) print(f'\n学習用データ\n{df_train}') # 検証用データを取得・表示 query_validation = 'select "value", "year" from "e_stat_go_jp_minkan_kyuyo_db"."e_stat_go_jp_minkan_kyuyo_table" where 2012 <= year and year < 2018;' df_validation = pd.read_sql(query_validation, conn) print(f'\n検証用データ\n{df_validation}') # テスト用データを取得・表示 query_test = 'select "value", "year" from "e_stat_go_jp_minkan_kyuyo_db"."e_stat_go_jp_minkan_kyuyo_table" where 2018 <= year;' df_test = pd.read_sql(query_test, conn) print(f'\nテスト用データ\n{df_test}')
df_train が学習用データ、df_validation が検証用データ、df_test がテスト用データです。
それぞれ確認のために print 関数で表示しています。
出力結果はこちら。
学習用データ
value year
0 4078000 1994
1 4107000 1995
2 4118000 1996
3 4183000 1997
4 4185000 1998
5 4032000 1999
6 4082000 2000
7 4001000 2001
8 3887000 2002
9 3753000 2003
10 3766000 2004
11 3710000 2005
12 3670000 2006
13 3672000 2007
14 3652000 2008
15 3502000 2009
16 3547000 2010
17 3583000 2011
検証用データ
value year
0 3521000 2012
1 3595000 2013
2 3614000 2014
3 3612000 2015
4 3562000 2016
5 3671000 2017
テスト用データ
value year
0 3716000 2018
1 3879000 2019
2 3701000 2020
2.3 取得したデータのプロファイルレポートを表示
ここで、pandas-profilingを使用して、取得したデータ(学習用データ)のプロファイルレポートを表示してみます。
以下のコードを実行します。
import pandas_profiling # 学習用データのプロファイルレポートを表示 df_train.profile_report()
データフレームに格納されたデータの全体像が、HTML形式でレポート出力されます。
(全部載せるのはコード量が多すぎるので、スクリーンショットだけ……)
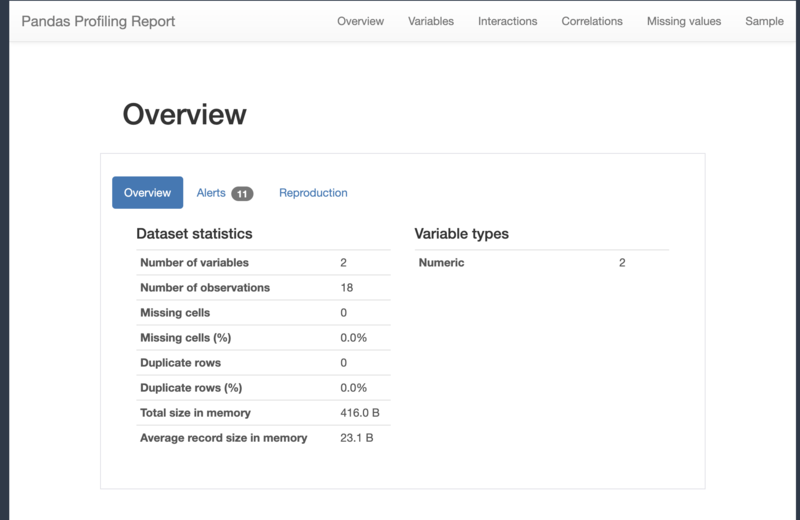
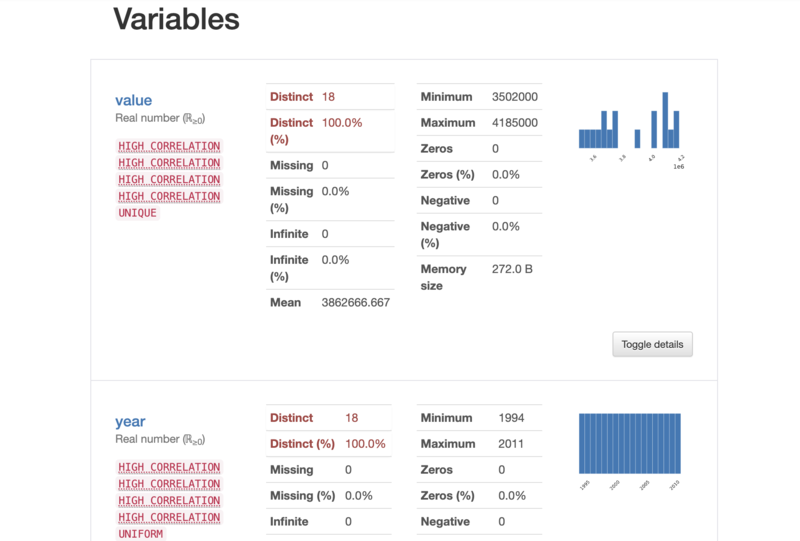
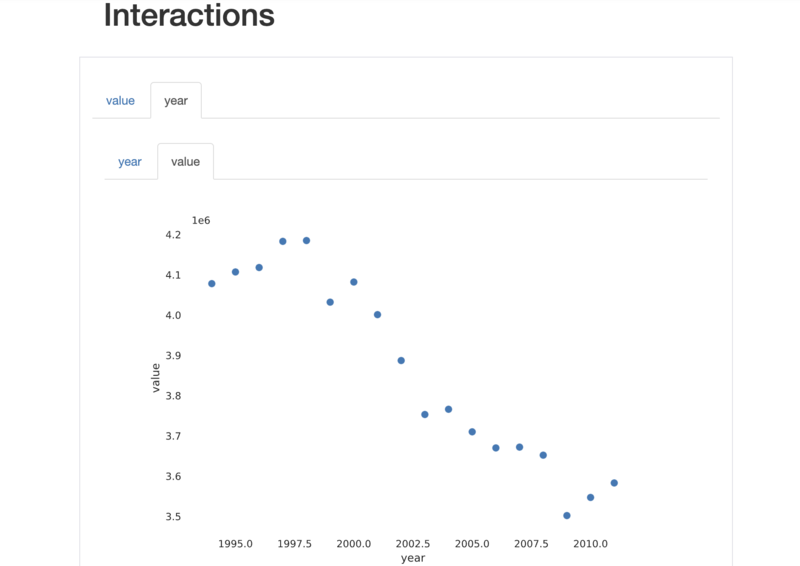
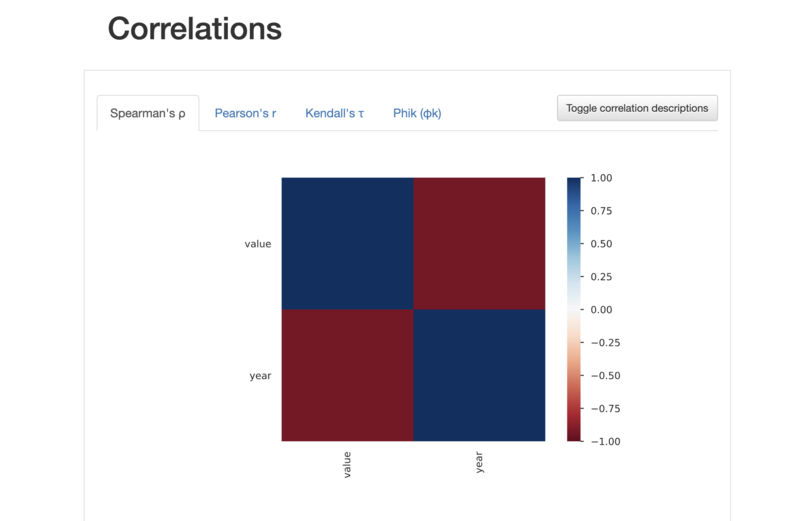
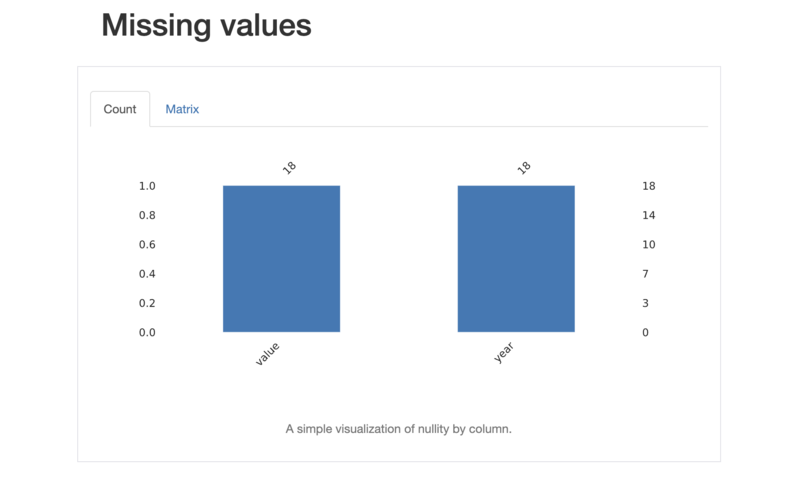
このように、データの列毎の詳細情報や、データの相関関係、欠損値などの情報を見ることができます。
本来であれば、このレポートを元にデータの調整を行ったりするのですが……
今回は単純なデータなのと、実践優先のため、レポートの表示のみに留めて先に進みます。
参考:pandas-profilingのGitHubリポジトリ
2.4 学習用データと検証用データをS3バケットに配置する
次は、学習用と検証用に分けておいたデータをS3バケットに配置します。
その後、S3に配置したデータから、SageMakerのSDKを通じて学習用アルゴリズムへ入力するためのデータを作成します。
import sagemaker # 学習用アルゴリズムへの入力/出力を配置するS3バケット # Session().default_bucket()を指定すると、"sagemaker-{region}-{aws-account-id}”という名前のS3バケットが使用される output_bucket = sagemaker.Session().default_bucket() # S3バケットのプレフィックス output_prefix = "sagemaker/aota_liner_learner_4" # 学習用データのS3上の場所 s3_train_data = f"s3://{output_bucket}/{output_prefix}/train" print(f"training files will be taken from: {s3_train_data}") # 検証用データのS3上の場所 s3_validation_data = f"s3://{output_bucket}/{output_prefix}/validation" print(f"validation files will be taken from: {s3_validation_data}") # 出力されるデータ(モデルなど)のS3上の場所 output_location = f"s3://{output_bucket}/{output_prefix}/output" print(f"training artifacts output location: {output_location}") # S3上に学習用データと検証用データを配置 df_train.to_csv(f"{s3_train_data}/minkan_kyuyo.csv", index=False, header=False) df_validation.to_csv(f"{s3_validation_data}/minkan_kyuyo.csv", index=False, header=False) # 上記でS3に配置したデータから、SageMakerのSDKを通じて学習用アルゴリズムへ入力するためのデータを作成 # 入力データを、sagemaker.inputs.TrainingInputという形式(Pythonのクラス)で作成 # 学習用データ train_data = sagemaker.inputs.TrainingInput( s3_train_data, distribution="FullyReplicated", content_type="text/csv", s3_data_type="S3Prefix", record_wrapping=None, compression=None, ) print(train_data.config) # 検証用データ validation_data = sagemaker.inputs.TrainingInput( s3_data=s3_validation_data , distribution="FullyReplicated", content_type="text/csv", s3_data_type="S3Prefix", record_wrapping=None, compression=None, ) print(validation_data.config)
出力結果:
training files will be taken from: s3://sagemaker-ap-northeast-1-XXXXXXXXXXXX/sagemaker/aota_liner_learner_4/train validation files will be taken from: s3://sagemaker-ap-northeast-1-XXXXXXXXXXXX/sagemaker/aota_liner_learner_4/validation training artifacts output location: s3://sagemaker-ap-northeast-1-XXXXXXXXXXXX/sagemaker/aota_liner_learner_4/output {'DataSource': {'S3DataSource': {'S3DataType': 'S3Prefix', 'S3Uri': 's3://sagemaker-ap-northeast-1-XXXXXXXXXXXX/sagemaker/aota_liner_learner_4/train', 'S3DataDistributionType': 'FullyReplicated'}}, 'ContentType': 'text/csv'} {'DataSource': {'S3DataSource': {'S3DataType': 'S3Prefix', 'S3Uri': 's3://sagemaker-ap-northeast-1-XXXXXXXXXXXX/sagemaker/aota_liner_learner_4/validation', 'S3DataDistributionType': 'FullyReplicated'}}, 'ContentType': 'text/csv'}
S3のバケットにも、ファイルが作成されていますね。
早速データを投入して学習! といきたいところですが、もう少しだけ準備が必要です……
3. 学習用アルゴリズムにデータを投入して、学習させる
3.1 SageMakerの線形学習アルゴリズムのコンテナイメージURIを取得する
上記でも触れましたが、今回はSageMakerの組み込み学習アルゴリズム、線形学習アルゴリズムを使用していきます。
こちらはDockerイメージとして提供されているので、以下のコードを使用して、SageMakerのSDKからイメージURIを取得しています。
import boto3 from sagemaker.image_uris import retrieve # sagemaker.image_uris.retrieveを使用して、線形学習アルゴリズム(linear-learner)のコンテナイメージURIを取得 container = retrieve("linear-learner", boto3.Session().region_name, version="1") print(container)
出力結果:
351501993468.dkr.ecr.ap-northeast-1.amazonaws.com/linear-learner:1
3.2 線形学習アルゴリズムの設定をする
続いて、線形学習アルゴリズムを使用する際の設定を行なっていきます。
学習アルゴリズムを実行するEstimator(推定器)を作成して、最低限必要なハイパーパラメータを設定します。
ハイパーパラメータは、機械学習のアルゴリズムを実行する際に、データから直接決めることができず、人の手であらかじめ決めておく必要のあるパラメータ(設定値)です。
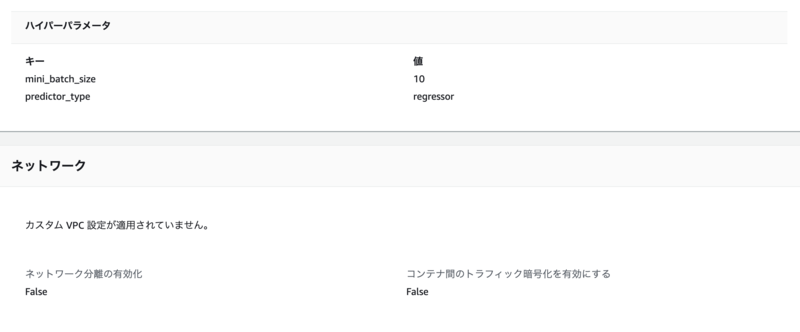
線形学習アルゴリズムでもいくつかハイパーパラメータがある(線形学習のハイパーパラメータ 参照)のですが、今回は最低限必要なパラメータとして、以下のように設定しました。
- predictor_type:regressor(回帰)
- 回帰の他には、binary_classifier(二項分類)、multiclass_classifier(複数クラス分類)というものがあります
- mini_batch_size:10
- バッチサイズ(一回の学習に使うデータ数)
- 今回はデータ数が少ないため、10に設定
- その他のパラメータはデフォルト値を使用
コードは以下のようになりました。
sess = sagemaker.Session() role="arn:aws:iam::XXXXXXXXXXXX:role/service-role/AmazonSageMaker-ExecutionRole-20210727T175770" # 学習アルゴリズムを実行するEstimator(推定器)を作成 linear = sagemaker.estimator.Estimator( container, role, instance_count=1, instance_type="ml.m4.xlarge", output_path=output_location, sagemaker_session=sess, ) # 最低限必要なハイパーパラメータを設定 linear.set_hyperparameters( predictor_type="regressor", mini_batch_size=10, )
ハイパーパラメータの他には、学習する際に使うインスタンスタイプや結果の出力先、先ほど取得したDockerイメージのURIなどを設定しています。
3.3 線形学習アルゴリズムにデータを投入して、学習させる
ようやくここまできました。いよいよ、線形学習アルゴリズムにデータを投入して学習させていきます!
せっかくなので、学習にかかった時間も計測しておきましょう。
コードは以下のようになります。
%%time # ↑学習にかかった時間を計測 from time import gmtime, strftime # ジョブ名を設定 job_name = "aota-linear-learner-4-" + strftime("%H-%M-%S", gmtime()) print("Training job", job_name) # Estimator(推定器)にデータを投入して学習させる linear.fit(inputs={'train': train_data, 'validation': validation_data}, job_name=job_name, wait=True, logs='All')
学習に少し時間がかかりますので、しばらく待機します……
4分ちょっと経過後、学習が終わったようです!
Training job aota-linear-learner-4-03-51-54 2022-07-31 03:51:54 Starting - Starting the training job... 2022-07-31 03:52:19 Starting - Preparing the instances for trainingProfilerReport-1659239514: InProgress ......... 2022-07-31 03:53:44 Downloading - Downloading input data... 2022-07-31 03:54:18 Training - Downloading the training image...... 2022-07-31 03:55:18 Training - Training image download completed. Training in progress..Docker entrypoint called with argument(s): train Running default environment configuration script [07/31/2022 03:55:23 INFO 140408747497280] Reading default configuration from /opt/amazon/lib/python3.7/site-packages/algorithm/resources/default-input.json: {'mini_batch_size': '1000', 'epochs': '15', 'feature_dim': 'auto', 'use_bias': 'true', 'binary_classifier_model_selection_criteria': 'accuracy', 'f_beta': '1.0', 'target_recall': '0.8', 'target_precision': '0.8', 'num_models': 'auto', 'num_calibration_samples': '10000000', 'init_method': 'uniform', 'init_scale': '0.07', 'init_sigma': '0.01', 'init_bias': '0.0', 'optimizer': 'auto', 'loss': 'auto', 'margin': '1.0', 'quantile': '0.5', 'loss_insensitivity': '0.01', 'huber_delta': '1.0', 'num_classes': '1', 'accuracy_top_k': '3', 'wd': 'auto', 'l1': 'auto', 'momentum': 'auto', 'learning_rate': 'auto', 'beta_1': 'auto', 'beta_2': 'auto', 'bias_lr_mult': 'auto', 'bias_wd_mult': 'auto', 'use_lr_scheduler': 'true', 'lr_scheduler_step': 'auto', 'lr_scheduler_factor': 'auto', 'lr_scheduler_minimum_lr': 'auto', 'positive_example_weight_mult': '1.0', 'balance_multiclass_weights': 'false', 'normalize_data': 'true', 'normalize_label': 'auto', 'unbias_data': 'auto', 'unbias_label': 'auto', 'num_point_for_scaler': '10000', '_kvstore': 'auto', '_num_gpus': 'auto', '_num_kv_servers': 'auto', '_log_level': 'info', '_tuning_objective_metric': '', 'early_stopping_patience': '3', 'early_stopping_tolerance': '0.001', '_enable_profiler': 'false'} [07/31/2022 03:55:23 INFO 140408747497280] Merging with provided configuration from /opt/ml/input/config/hyperparameters.json: {'mini_batch_size': '10', 'predictor_type': 'regressor'} [07/31/2022 03:55:23 INFO 140408747497280] Final configuration: {'mini_batch_size': '10', 'epochs': '15', 'feature_dim': 'auto', 'use_bias': 'true', 'binary_classifier_model_selection_criteria': 'accuracy', 'f_beta': '1.0', 'target_recall': '0.8', 'target_precision': '0.8', 'num_models': 'auto', 'num_calibration_samples': '10000000', 'init_method': 'uniform', 'init_scale': '0.07', 'init_sigma': '0.01', 'init_bias': '0.0', 'optimizer': 'auto', 'loss': 'auto', 'margin': '1.0', 'quantile': '0.5', 'loss_insensitivity': '0.01', 'huber_delta': '1.0', 'num_classes': '1', 'accuracy_top_k': '3', 'wd': 'auto', 'l1': 'auto', 'momentum': 'auto', 'learning_rate': 'auto', 'beta_1': 'auto', 'beta_2': 'auto', 'bias_lr_mult': 'auto', 'bias_wd_mult': 'auto', 'use_lr_scheduler': 'true', 'lr_scheduler_step': 'auto', 'lr_scheduler_factor': 'auto', 'lr_scheduler_minimum_lr': 'auto', 'positive_example_weight_mult': '1.0', 'balance_multiclass_weights': 'false', 'normalize_data': 'true', 'normalize_label': 'auto', 'unbias_data': 'auto', 'unbias_label': 'auto', 'num_point_for_scaler': '10000', '_kvstore': 'auto', '_num_gpus': 'auto', '_num_kv_servers': 'auto', '_log_level': 'info', '_tuning_objective_metric': '', 'early_stopping_patience': '3', 'early_stopping_tolerance': '0.001', '_enable_profiler': 'false', 'predictor_type': 'regressor'} [07/31/2022 03:55:23 WARNING 140408747497280] Loggers have already been setup. Process 1 is a worker. [07/31/2022 03:55:23 INFO 140408747497280] Using default worker. [07/31/2022 03:55:23 INFO 140408747497280] Checkpoint loading and saving are disabled. [07/31/2022 03:55:23 INFO 140408747497280] Create Store: local [07/31/2022 03:55:23 INFO 140408747497280] Scaler algorithm parameters <algorithm.scaler.ScalerAlgorithmStable object at 0x7fb2fd383490> [07/31/2022 03:55:23 INFO 140408747497280] Scaling model computed with parameters: {'stdev_label': [127495.25] <NDArray 1 @cpu(0)>, 'stdev_weight': [2.8722813] <NDArray 1 @cpu(0)>, 'mean_label': [4042600.] <NDArray 1 @cpu(0)>, 'mean_weight': [1998.5] <NDArray 1 @cpu(0)>} [07/31/2022 03:55:23 INFO 140408747497280] nvidia-smi: took 0.032 seconds to run. [07/31/2022 03:55:23 INFO 140408747497280] nvidia-smi identified 0 GPUs. [07/31/2022 03:55:23 INFO 140408747497280] Number of GPUs being used: 0 #metrics {"StartTime": 1659239723.6741629, "EndTime": 1659239723.6742313, "Dimensions": {"Algorithm": "Linear Learner", "Host": "algo-1", "Operation": "training", "Meta": "init_train_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 28.0, "count": 1, "min": 28, "max": 28}, "Total Batches Seen": {"sum": 3.0, "count": 1, "min": 3, "max": 3}, "Max Records Seen Between Resets": {"sum": 18.0, "count": 1, "min": 18, "max": 18}, "Max Batches Seen Between Resets": {"sum": 2.0, "count": 1, "min": 2, "max": 2}, "Reset Count": {"sum": 2.0, "count": 1, "min": 2, "max": 2}, "Number of Records Since Last Reset": {"sum": 0.0, "count": 1, "min": 0, "max": 0}, "Number of Batches Since Last Reset": {"sum": 0.0, "count": 1, "min": 0, "max": 0}}} #metrics {"StartTime": 1659239723.7357469, "EndTime": 1659239723.7358181, "Dimensions": {"Algorithm": "Linear Learner", "Host": "algo-1", "Operation": "training", "epoch": 0, "model": 0}, "Metrics": {"train_mse_objective": {"sum": 1.010321807861328, "count": 1, "min": 1.010321807861328, "max": 1.010321807861328}}} 〜中略〜 #metrics {"StartTime": 1659239725.292417, "EndTime": 1659239725.2924323, "Dimensions": {"Algorithm": "Linear Learner", "Host": "algo-1", "Operation": "training", "epoch": 13, "model": 30}, "Metrics": {"validation_mse_objective": {"sum": 233238429696.0, "count": 1, "min": 233238429696.0, "max": 233238429696.0}}} #metrics {"StartTime": 1659239725.2924812, "EndTime": 1659239725.2924972, "Dimensions": {"Algorithm": "Linear Learner", "Host": "algo-1", "Operation": "training", "epoch": 13, "model": 31}, "Metrics": {"validation_mse_objective": {"sum": 257370598058.66666, "count": 1, "min": 257370598058.66666, "max": 257370598058.66666}}} [07/31/2022 03:55:25 INFO 140408747497280] #quality_metric: host=algo-1, epoch=13, validation mse_objective <loss>=165634856277.33334 [07/31/2022 03:55:25 INFO 140408747497280] #early_stopping_criteria_metric: host=algo-1, epoch=13, criteria=mse_objective, value=30914439850.666668 [07/31/2022 03:55:25 INFO 140408747497280] Saving model for epoch: 13 [07/31/2022 03:55:25 INFO 140408747497280] Saved checkpoint to "/tmp/tmpo35q1i6h/mx-mod-0000.params" [07/31/2022 03:55:25 INFO 140408747497280] Early stop condition met. Stopping training. [07/31/2022 03:55:25 INFO 140408747497280] #progress_metric: host=algo-1, completed 100 % epochs #metrics {"StartTime": 1659239725.1847978, "EndTime": 1659239725.3000724, "Dimensions": {"Algorithm": "Linear Learner", "Host": "algo-1", "Operation": "training", "epoch": 13, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 280.0, "count": 1, "min": 280, "max": 280}, "Total Batches Seen": {"sum": 31.0, "count": 1, "min": 31, "max": 31}, "Max Records Seen Between Resets": {"sum": 18.0, "count": 1, "min": 18, "max": 18}, "Max Batches Seen Between Resets": {"sum": 2.0, "count": 1, "min": 2, "max": 2}, "Reset Count": {"sum": 16.0, "count": 1, "min": 16, "max": 16}, "Number of Records Since Last Reset": {"sum": 18.0, "count": 1, "min": 18, "max": 18}, "Number of Batches Since Last Reset": {"sum": 2.0, "count": 1, "min": 2, "max": 2}}} [07/31/2022 03:55:25 INFO 140408747497280] #throughput_metric: host=algo-1, train throughput=155.9272342745733 records/second [07/31/2022 03:55:25 WARNING 140408747497280] wait_for_all_workers will not sync workers since the kv store is not running distributed [07/31/2022 03:55:25 WARNING 140408747497280] wait_for_all_workers will not sync workers since the kv store is not running distributed [07/31/2022 03:55:25 INFO 140408747497280] #early_stopping_criteria_metric: host=algo-1, epoch=13, criteria=mse_objective, value=30914439850.666668 [07/31/2022 03:55:25 INFO 140408747497280] #validation_score (algo-1) : ('mse_objective', 6361709226.666667) [07/31/2022 03:55:25 INFO 140408747497280] #validation_score (algo-1) : ('mse', 6361709226.666667) [07/31/2022 03:55:25 INFO 140408747497280] #validation_score (algo-1) : ('absolute_loss', 56318.666666666664) [07/31/2022 03:55:25 INFO 140408747497280] #validation_score (algo-1) : ('rmse', 79760.32363692281) [07/31/2022 03:55:25 INFO 140408747497280] #validation_score (algo-1) : ('r2', -1.939150552585311) [07/31/2022 03:55:25 INFO 140408747497280] #validation_score (algo-1) : ('mae', 56318.666666666664) [07/31/2022 03:55:25 INFO 140408747497280] #quality_metric: host=algo-1, validation mse_objective <loss>=6361709226.666667 [07/31/2022 03:55:25 INFO 140408747497280] #quality_metric: host=algo-1, validation mse <loss>=6361709226.666667 [07/31/2022 03:55:25 INFO 140408747497280] #quality_metric: host=algo-1, validation absolute_loss <loss>=56318.666666666664 [07/31/2022 03:55:25 INFO 140408747497280] #quality_metric: host=algo-1, validation rmse <loss>=79760.32363692281 [07/31/2022 03:55:25 INFO 140408747497280] #quality_metric: host=algo-1, validation r2 <loss>=-1.939150552585311 [07/31/2022 03:55:25 INFO 140408747497280] #quality_metric: host=algo-1, validation mae <loss>=56318.666666666664 [07/31/2022 03:55:25 INFO 140408747497280] Best model found for hyperparameters: {"optimizer": "adam", "learning_rate": 0.1, "wd": 0.01, "l1": 0.0, "lr_scheduler_step": 10, "lr_scheduler_factor": 0.99, "lr_scheduler_minimum_lr": 0.0001} [07/31/2022 03:55:25 INFO 140408747497280] Saved checkpoint to "/tmp/tmppxlofd1m/mx-mod-0000.params" [07/31/2022 03:55:25 INFO 140408747497280] Test data is not provided. #metrics {"StartTime": 1659239723.45235, "EndTime": 1659239725.3872015, "Dimensions": {"Algorithm": "Linear Learner", "Host": "algo-1", "Operation": "training"}, "Metrics": {"initialize.time": {"sum": 210.7985019683838, "count": 1, "min": 210.7985019683838, "max": 210.7985019683838}, "epochs": {"sum": 15.0, "count": 1, "min": 15, "max": 15}, "check_early_stopping.time": {"sum": 10.718107223510742, "count": 15, "min": 0.1957416534423828, "max": 1.4944076538085938}, "update.time": {"sum": 1561.516523361206, "count": 14, "min": 92.32616424560547, "max": 137.47334480285645}, "finalize.time": {"sum": 77.8505802154541, "count": 1, "min": 77.8505802154541, "max": 77.8505802154541}, "setuptime": {"sum": 31.870365142822266, "count": 1, "min": 31.870365142822266, "max": 31.870365142822266}, "totaltime": {"sum": 2205.627679824829, "count": 1, "min": 2205.627679824829, "max": 2205.627679824829}}} 2022-07-31 03:55:42 Uploading - Uploading generated training model 2022-07-31 03:55:42 Completed - Training job completed Training seconds: 118 Billable seconds: 118 CPU times: user 669 ms, sys: 103 ms, total: 772 ms Wall time: 4min 13s
意外とあっけなく学習が終わりました。("機械"学習なので当然といえば当然ですが)
実施した学習(トレーニングジョブ)については、AWSコンソールのSageMakerの画面で、「トレーニング」⇨「トレーニングジョブ」を選択すると、情報を見ることができます。
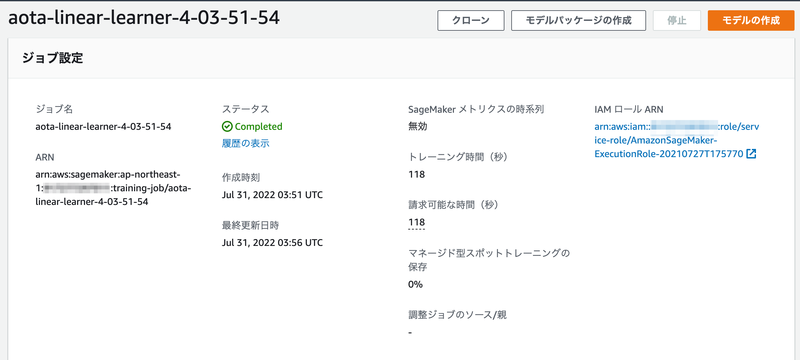
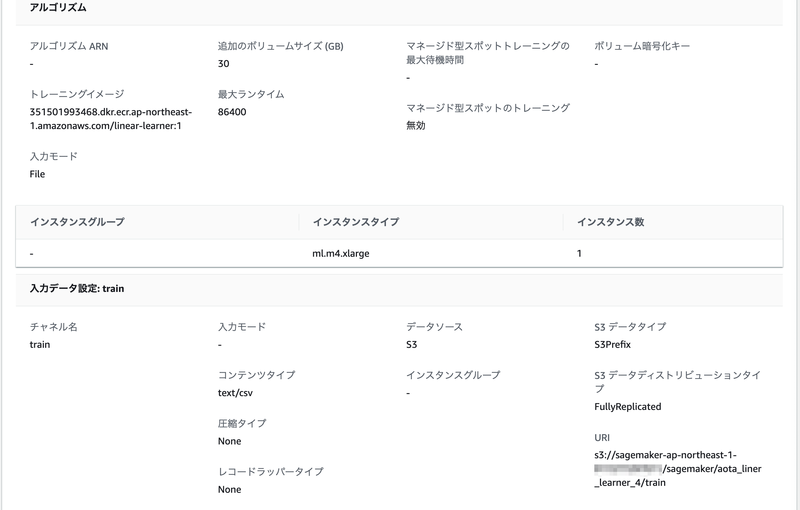
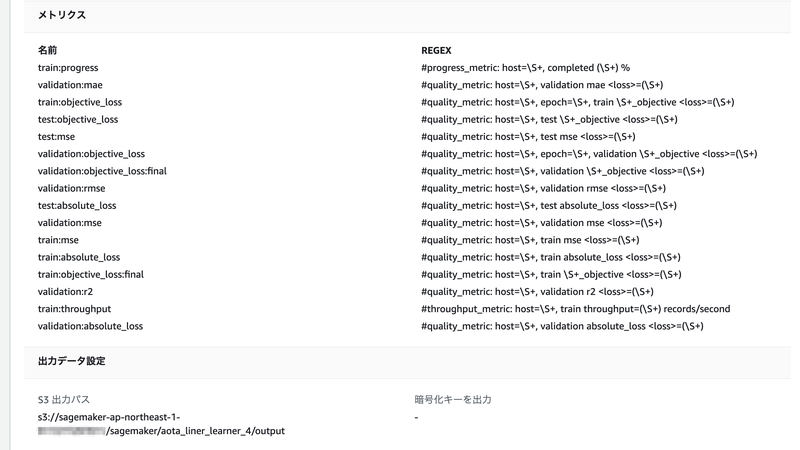
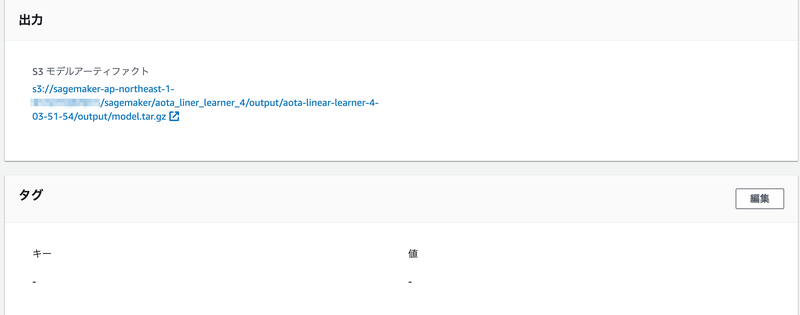
「出力」の「S3 モデルアーティファクト」を見てみると、学習済みのモデルはS3に model.tar.gz という名前で保存されているみたいですね。
では、この学習済みのモデルを使って、テストデータで実際に予測(推論)をしてみましょう!
4. 推論用のエンドポイントを作って、予測してみる
4.1 推論用のエンドポイントを作る
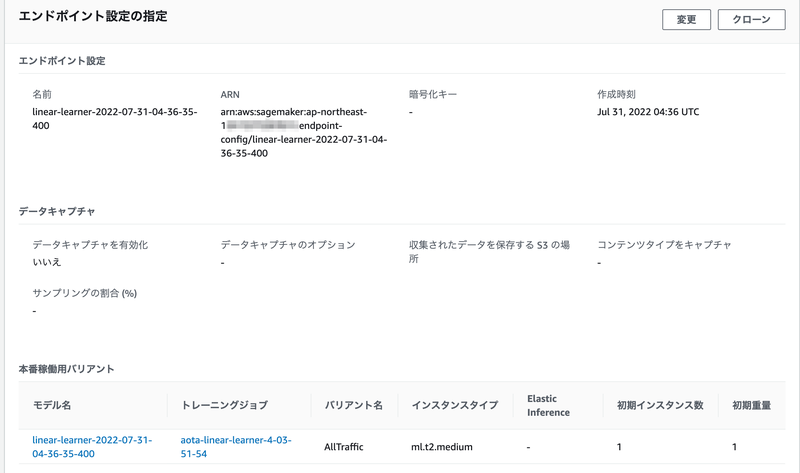
まずは、先ほど学習が済んだモデルを使って、推論用のエンドポイントを作成します。
コードは以下の通りです。
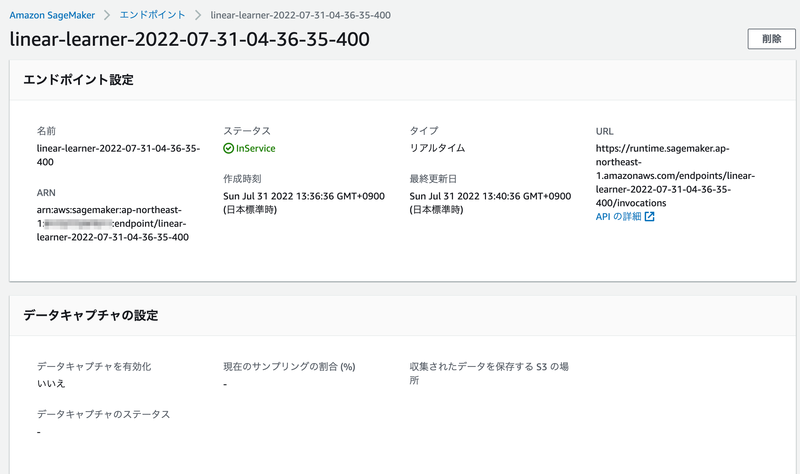
%%time # ↑エンドポイント作成にかかった時間を計測 # 学習済みのモデルを使って、推論用のエンドポイントを作成 linear_predictor = linear.deploy(initial_instance_count=1, instance_type="ml.t2.medium") print(f"\ncreated endpoint: {linear_predictor.endpoint_name}")
ここでも一応時間を計測しています。
インスタンスタイプは ml.t2.medium を選択してみました。
エンドポイントが作成されるまで、しばし待ちます…約4分後、作成できたようです。
created endpoint: linear-learner-20220731043635-400 CPU times: user 139 ms, sys: 25.1 ms, total: 164 ms Wall time: 4min 1s
エンドポイントの情報も、AWSコンソールのSageMakerの画面で、「推論」⇨「エンドポイント」から確認することができます。
4.2 エンドポイントを呼び出して、テスト用データで推論してみる
エンドポイントが作成できたので、テスト用のデータで実際に推論してみます。
まず、テスト用のデータは、以下のようになっていました。
value year 0 3716000 2018 1 3879000 2019 2 3701000 2020
2018年〜2020年までのデータを推論してもらって、実際にテスト用データに入っている値と比べてみたいと思います。
以下のようなコードを書きました。
from sagemaker.serializers import CSVSerializer from sagemaker.deserializers import JSONDeserializer # エンドポイントで、CSVの入力とJSONでのレスポンスができるように設定 linear_predictor.serializer = CSVSerializer() linear_predictor.deserializer = JSONDeserializer() year_list = [] predicted_value_list = [] actual_value_list = [] residual_list = [] for year in df_test['year']: result = linear_predictor.predict([year]) predicted_value = round(result['predictions'][0]['score']) actual_value = df_test[df_test['year'] == year]['value'].iloc[-1] year_list.append(year) predicted_value_list.append(predicted_value) actual_value_list.append(actual_value) residual_list.append(predicted_value - actual_value) result_df = pd.DataFrame( data={ 'year': year_list, 'predicted_value': predicted_value_list, 'actual_value': actual_value_list, 'residual': residual_list } ) print(result_df)
年度ごとに、以下の値を出力するようにしました。
- 推論によって予測された値:predicted_value
- 実際にテスト用データに入っている値:actual_value
- 予測値と実際の値の差(残差):residual
では、コードを実行して推論してもらいましょう!
出力結果:
year predicted_value actual_value residual 0 2018 3520904 3716000 -195096 1 2019 3497432 3879000 -381568 2 2020 3473964 3701000 -227036
うーん、実際の値とは結構差がありますね……
でも、せっかく作ったので、もっと未来のデータも推論してみましょう!
以下のコードを実行して、2030年の平均給与額を単発で推論してみます。
result = linear_predictor.predict(['2030']) print(round(result['predictions'][0]['score']))
出力結果:
3239268
中々世知辛い結果となってしまいました……(´・_・`)
5. お片付け
※本記事の内容を見て一緒に実践してくださっている方、ありがとうございます! お片付けの手順は必要に応じて実施ください。
データを作って、加工して、学習させて、推論させる、の一通りの流れを実践することができました。 それでは、名残惜しいですがお片付けに入っていきます。
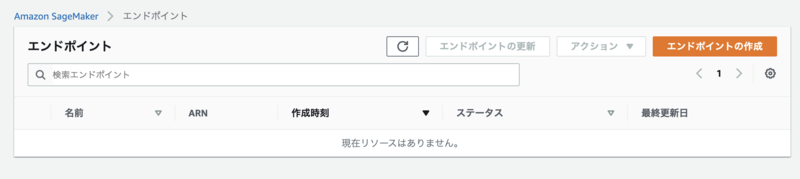
と言っても、以下のコードを実行して、推論用のエンドポイントを削除するだけです。
sagemaker.Session().delete_endpoint(linear_predictor.endpoint_name)
AWSコンソールからも、エンドポイントが削除されたことが確認できました。
おわりに
今回の実践はここまでとなります。
データ作成から推論までの一通りの流れを追うだけでも、前提となる知識がたくさん必要となるので本当に大変ですね(;´ー`)
次回は、今回1つだった説明変数を増やしてみて、もう一度分析を実践していく予定です。
発表まであとわずか、さらに実践を重ねていきたいと思います!
参考情報リンクまとめ
- 2022/8/7 JAWS-UG京都
- Amazon SageMaker を初めてお使いになる方向けの情報
- Amazon SageMaker ドメインにオンボードする
- e-Stat 政府統計の総合窓口
- 線形学習アルゴリズム
- 線形学習アルゴリズムの入出力インターフェイス
- pandas-profilingのGitHubリポジトリ
- 線形学習のハイパーパラメータ
MLOps への道 記事一覧
- MLOps への道① 〜Amazon SageMaker で線形回帰を行う〜 ←本記事です
- MLOps への道② 〜SageMaker Model Building Pipelinesでモデルの学習・登録パイプラインを作る〜
※②については、JAWS-UG京都での発表内容も踏まえて内容変更しました