この記事は、前回の MLOps への道② の続きです。前回の記事をまだお読みでなければ、先にご一読いただけると幸いです。
こんにちは! GIMLE チームの太田です。
年末も近づいてきて、寒さも増してきましたね 彡(-_-;)彡
しっかり暖かくして、冬を乗り切っていきましょう!
今回は、MLOps への道シリーズ、第3弾です!
※本シリーズは「できるだけシンプルに」「End To Endで」継続的学習・デプロイ基盤の作成に至るまでの過程を実践してみよう、という想いのもとで執筆しております。扱うデータの内容や学習アルゴリズムの詳細、推論結果の解釈の仕方など、機械学習のディープな部分にはあまり踏み込まない予定ですので、ご留意いただければ幸いです
- はじめに
- 前提となる知識・用語
- 1. SageMaker Projectの作成
- 2. CodeCommitから、ソースコードをクローンする
- 3. 推論用エンドポイント(ステージング)を作成する
- 4. 推論用エンドポイント(本番)を作成する
- 5. 新たなモデルをModel Registryに登録して、デプロイパイプラインを動かす
- 6. お片付け
- おわりに
- 参考情報リンクまとめ
- MLOps への道 記事一覧
はじめに
さて、前回の記事では、アルゴリズムにデータを投入し、学習させて、学習済みモデルを Model Registry に登録するまでの流れを実践してみました。
以下の構成図の左上の部分でしたね。

第3回目となる今回は、CodePipelineを使用して、Model Registryに登録した学習済みモデルを継続してデプロイする仕組みを構築していこうと思います。
構成図でいくと、右半分にあたる箇所ですね。

作業はAWSマネジメントコンソールおよびSagemaker Studioでやっていくことになりますが、前回同様、SageMaker Studioのセットアップ方法・起動方法については割愛させていただきます。
実践の大まかな流れは、以下の通り。
- SageMaker Projectの作成
- CodeCommitから、ソースコードをクローンする
- 推論用エンドポイント(ステージング)を作成する
- 推論用エンドポイント(本番)を作成する
- 新たなモデルをModel Registryに登録して、デプロイパイプラインを動かす
- お片付け
では、MLOps への道③、進んでいきましょう!
前提となる知識・用語
前回記事の「前提となる知識・用語」 に加えて、以下の要素が登場します。 また、使用するモデルは、前回および前々回の記事で作成した、線形学習アルゴリズムで未来の平均給与額を予測するモデルとなります。
AWSに関すること
- 使用するAWSのサービス
- SageMaker
- SageMaker Project
- CloudFormation
- CodeCommit
- CodeBuild
- CodePipeline
- CloudShell
- SageMaker
1. SageMaker Projectの作成
まずは、SageMaker Project(以下、プロジェクト と記載)を作成していきます。
Sagemaker Studioにて、左側にあるSageMaker resourcesのアイコンを選択した後、ドロップダウンから [Projects] を選択し、[Create project] ボタンを選択すると、新規Projectの作成タブが開きます。
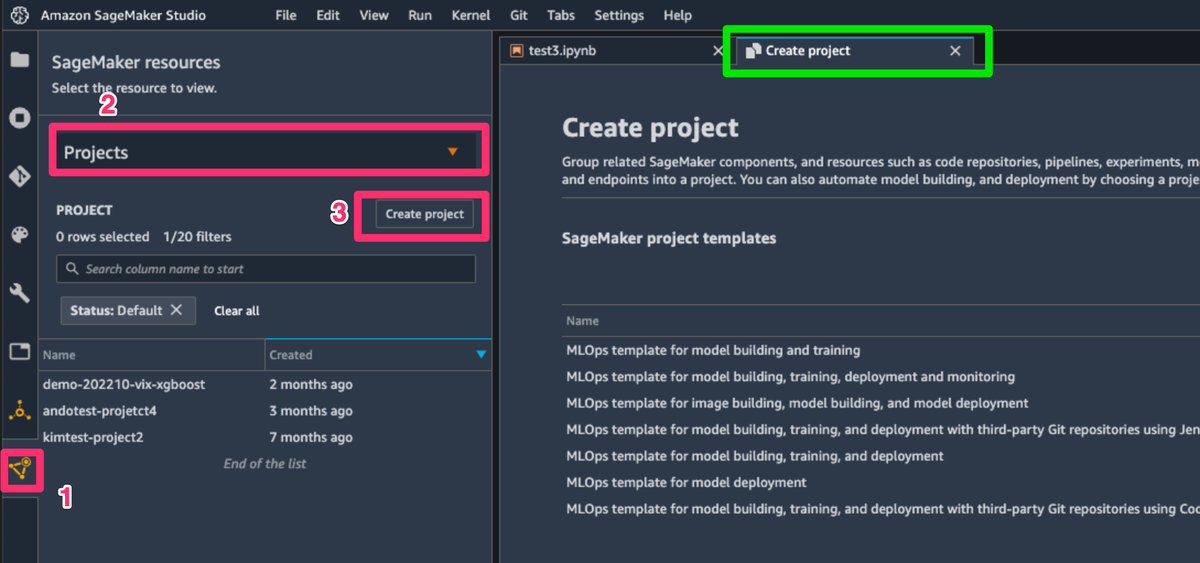
SageMaker templatesから、[MLOps template for model deployment] を選択して、右下の [Select project template] ボタンを選択します。

以下の設定を入力して、[Create project] ボタンを選択すると、プロジェクトの作成が始まります。
- Name
- 任意の名前を入力します
- Description
- 任意の説明を入力します
- SourceModelPackageGroupName
- 前回の記事の モデル登録ステップを定義する で定義したモデルグループの名前を入力します


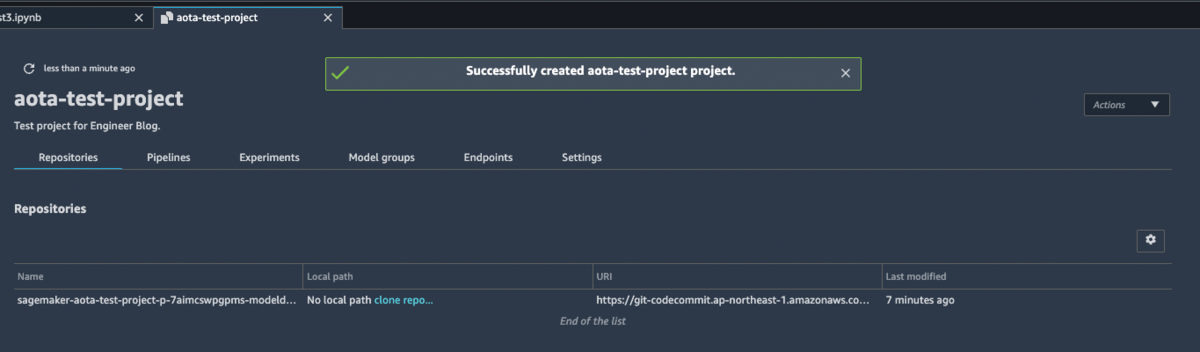
プロジェクトが作成されると、CodeCommitにリポジトリが作成されます。
次は、SageMaker Studioでソースコードが編集できるように、CodeCommitリポジトリからクローンしてきます。
2. CodeCommitから、ソースコードをクローンする
プロジェクトのタブにて、リポジトリのURIが表示されている部分を右クリックして、[Clone Repository] を選択します。

確認のウィンドウが開くので、そのまま [Clone Repository] ボタンを選択すると、ソースコードがクローンされます。


3. 推論用エンドポイント(ステージング)を作成する
3.1 パイプラインの実行結果を確認
プロジェクトを作った時点で、一度パイプラインが動いています。
CodePipelineの画面で、結果を見てみましょう。


あれ、Buildのフェーズで失敗していますね。
CodeBuildから、ログを確認してみることにします。

モデルパッケージグループに、承認(approved)されたモデルがないことが原因のようです。
SageMaker Studioからモデルを承認して、もう一度試してみましょう。
3.2 モデルの承認
Model registryから、プロジェクトに設定したモデルグループを選択し、デプロイ対象のバージョンで右クリック、[Update model version status...] を選択します。

ウィンドウが開くので、[Status] を Approved に変更して、[Update status] ボタンを選択します。

モデルのステータスが Approved になっていれば、承認完了です!

モデルの承認ができたので、もう一度、CodePipelineの画面に戻って、実行結果を見てみます。

今度はDeployStagingのフェーズで失敗しています。
次はCloudFormationの画面で、詳細を見てみることにしましょう。

インスタンスタイプがモデルで対応していないようです。
前回記事の モデル登録ステップを定義する で、推論用エンドポイントに使うインスタンス inference_instances に ml.m4.xlarge を設定したので、これと合っていないということですね。
(前回記事のソースコード抜粋)
# モデル登録ステップを定義
register_step = ModelStep(
name="ModelStep",
step_args=model.register(
content_types=["application/jsonlines"],
response_types=["application/jsonlines"],
inference_instances=["ml.m4.xlarge"], # ⇦ ここで推論用エンドポイントのインスタンスタイプを指定している
transform_instances=["ml.m4.xlarge"],
model_package_group_name=model_package_group_name
)
)
では、ソースコードを編集して、インスタンスタイプを合わせることにしましょう。
3.3 ソースコードを編集して、インスタンスタイプを変更する
先ほどCodeCommitからクローンしてきたファイルの中で、staging-config.json を編集します。
ファイル名をそのままダブルクリックすると編集できない状態でタブが開くため、ファイル名を右クリック - [Open With] - [Editor] の順に選択して編集します。

EndpointInstanceType を、モデル登録ステップにて設定したインスタンスタイプに合わせて変更して、保存します。
{
"Parameters": {
"StageName": "staging",
"EndpointInstanceCount": "1",
"EndpointInstanceType": "ml.m4.xlarge",
"SamplingPercentage": "100",
"EnableDataCapture": "true"
}
}
この状態でコミット、プッシュ……といきたいところですが、本番用推論エンドポイントの設定も更新しておきましょう。
prod-config.json を、ステージング用と同じように編集して保存します。
{
"Parameters": {
"StageName": "prod",
"EndpointInstanceCount": "1",
"EndpointInstanceType": "ml.m4.xlarge",
"SamplingPercentage": "80",
"EnableDataCapture": "true"
}
}
ファイル編集が終わったら、コミットとプッシュを行います。
SageMaker Studioのターミナルを開いてコマンドで実行するか、左側にあるGitメニューから実行できます。
プッシュができたら、再度パイプラインが動き出しますので、状態を確認していきましょう。
3.4 パイプラインの実行結果を確認
CodePipelineの画面で確認すると、今度はデプロイ成功していて、手動での承認待ちの状態になっています。

これで、推論用エンドポイント(ステージング)の作成までができました。
以下の構成図で、緑色の枠をつけた部分までが完了したことになります。

では、推論用エンドポイント(ステージング)を使って、試しに推論を行ってみましょう。
3.5 推論用エンドポイント(ステージング)を使って推論する
今回は、AWS CLIを使用して、CloudShellで推論を実行してみます。
CloudShellは、マネジメントコンソールの右上にあるアイコンをクリックすると、開きます。

CloudShellが開いたら、以下のコマンドを実行すると、 result.json ファイルに推論結果が出力されます。
aws sagemaker-runtime invoke-endpoint \
--endpoint-name <推論用エンドポイント(ステージング)の名前> \
--content-type text/csv \
--accept application/json \
--body $(echo -n 2030 | base64) \
result.json
コマンドは、 sagemaker-runtime invoke-endpoint を使用。
--body オプションにて、予測したい値(上記コマンドでは、2030年の平均給与額)を指定しています。
推論結果 :
{"predictions": [{"score": 3342168.0}]}
推論結果も返ってきていますね。
本来であれば、ステージング環境のエンドポイントを使って推論の精度などを検証した後、本番環境のエンドポイント作成を承認する流れとなりますが、今回そこはスキップして、本番環境の作成に進んでいくことにします。
4. 推論用エンドポイント(本番)を作成する
4.1 パイプラインで手動承認をする
では、承認待ちになっているパイプラインで、手動承認を行っていきましょう。
CodePipelineの画面で、ApproveDeploymentのフェーズにある [レビュー] ボタンを選択します。

レビューのウィンドウが開くので、[承認します] ボタンを選択します。

手動承認が完了すると、パイプラインが再び動き出します。
4.2 パイプラインの実行結果を確認
しばらく待機して、パイプラインの実行結果を見てみます。
成功しているようですね!
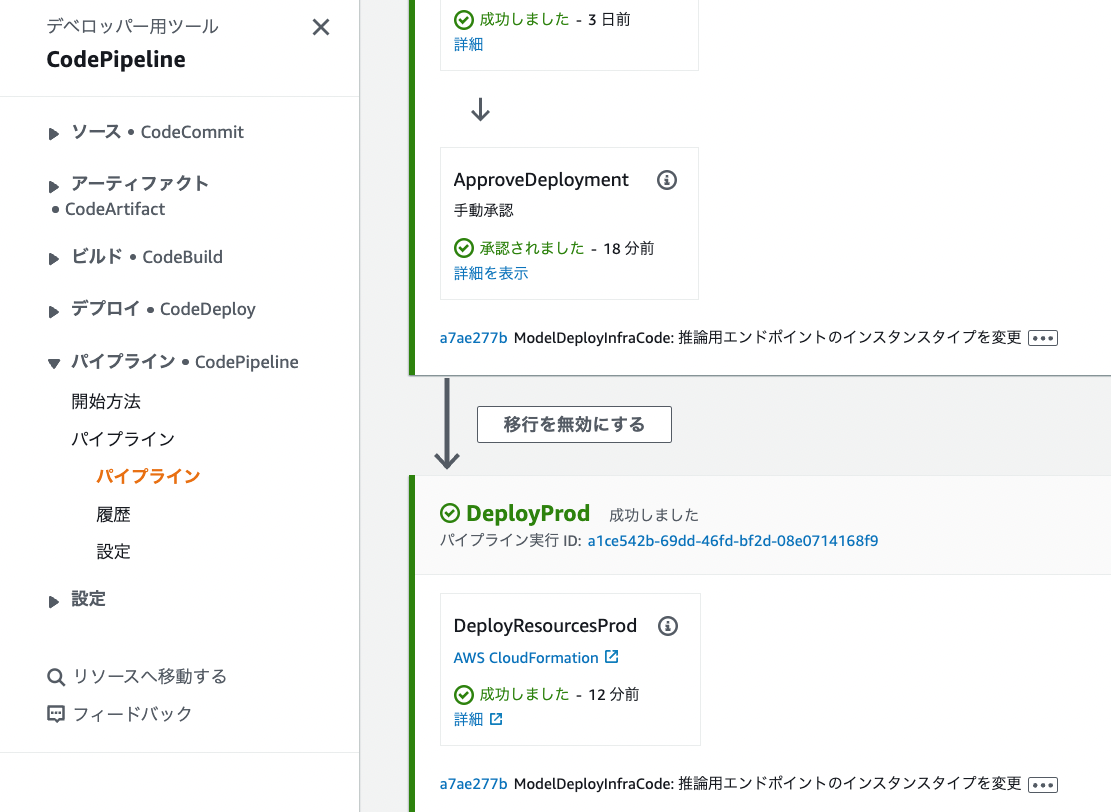
SageMakerの画面で [推論] - [エンドポイント] も確認。
本番環境のエンドポイントも、無事作成できたようです。

4.3 推論用エンドポイント(本番)を使って推論する
では、作成した本番環境のエンドポイントでも推論をやってみましょう。
CloudShellで以下のコマンドを実行します。
aws sagemaker-runtime invoke-endpoint \
--endpoint-name <推論用エンドポイント(本番)の名前> \
--content-type text/csv \
--accept application/json \
--body $(echo -n 2040 | base64) \
result.json
今度は、2040年の平均給与額を推論してみました。
推論結果 :
{"predictions": [{"score": 3140240.0}]}
これで、Model Registryに登録した学習済みモデルのデプロイが完了です。
以下の構成図でいくと、緑色の枠部分を一通り動作させることができました。

5. 新たなモデルをModel Registryに登録して、デプロイパイプラインを動かす
それでは最後に、SageMaker Pipelineの方を改めて実行して、Model Registryへ新しいモデル(モデルバージョン2)を登録してみます。
EventBridgeルールによって、モデルのデプロイパイプライン(CodePipeline)が起動されるところを見て、今回の実践は終了としたいと思います。
5.1 SageMaker Pipeline を動かす
前回記事の 学習ステップとモデル登録ステップを使って、パイプラインを作成する にて作成したパイプラインを動かしていきます。
SageMaker StudioのPipelinesから、前回作成したパイプラインを選択します。(パイプラインをダブルクリックすると、タブが開きます)

開いたタブの右側にある、[Create execution] ボタンを選択するとウィンドウが開くので、[Execution name] に任意の名前を設定して、[Start] ボタンを選択します。

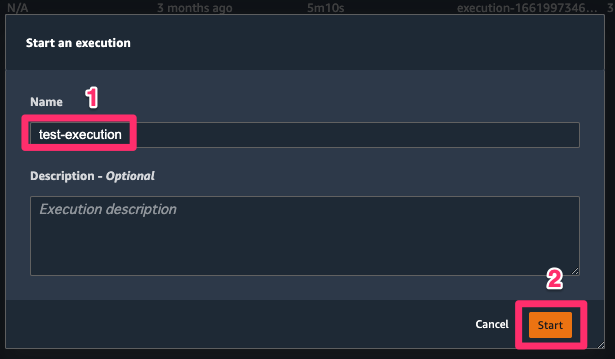
上記の操作で、パイプライン(SageMaker Pipeline)が進み出します。
実行状態の確認方法は、 前回記事の パイプラインを実行してみる の辺りに記載していますので、そちらを参照ください。

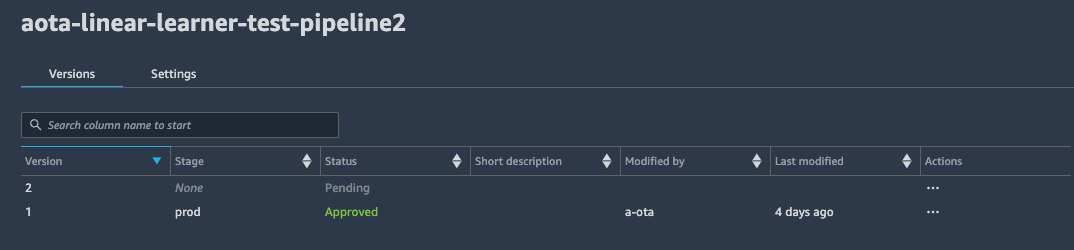
SageMaker Pipelineの実行が完了したら、CodePipelineの方も確認してみましょう。
モデルのデプロイパイプラインも動き始めているはずです。

ところで、先程 3. 推論用エンドポイント(ステージング)を作成する にて、承認(approved)されたモデルがないというエラーが発生していました。
先程SageMaker Pipelineを動かして作成したモデル(モデルバージョン2)も、まだ承認されていない状態なので、このモデルを承認しましょう。
5.2 モデルの承認
手順は、上記 3.2 モデルの承認 と同じなので、省略します。

モデルバージョン2の Stage が None になっているのは、モデルバージョン2が承認される前にデプロイパイプラインが動いてしまい、モデルバージョン1の方で推論エンドポイント(ステージング)が作成されてしまったことが理由と考えられます。
モデルの承認も含めてプロセスを最適化をするためには、SageMaker Pipelineの方と合わせてデプロイパイプラインを修正する必要がありそうです。(ここまでやると記事が長くなりそうなので、今回そこまでは踏み込みません)
5.3 パイプラインの手動承認で、却下する
このままでは推論エンドポイント(ステージング)が古いモデルのままなので、承認はできませんね。
ということで、デプロイパイプラインで却下することにします。
CodePipelineの画面で、ApproveDeploymentのフェーズにある [レビュー] ボタンを選択し、開いたウィンドウの [却下します] ボタンを選択します。
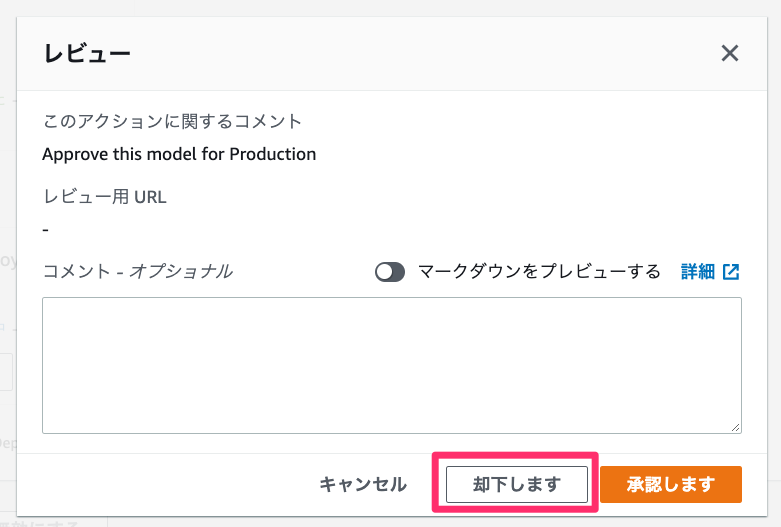
またデプロイパイプラインが動き出すので、しばらく待ちましょう。
手動承認待ちの状態になるまで進んだら、新しいモデルバージョンの状態を確認します。

モデルバージョン2で、推論用エンドポイント(ステージング)が作成されたようですね。
では、デプロイパイプラインを最後まで動かして、締めくくりとしましょう。
5.4 パイプラインで手動承認をする
手順は上記 4.1 パイプラインで手動承認をする と同じなので、省略します。
デプロイパイプラインが最後まで動作して、モデルバージョン2で、推論用エンドポイント(本番)が作成されました。


6. お片付け
モデルのデプロイパイプラインを作成して、動かすことができました。
ここからは、お片付けに入っていきます。
※本記事の内容を見て一緒に実践してくださっている方、ありがとうございます! お片付けの手順は必要に応じて実施ください。
6.1 SageMaker Projectの削除
SageMaker Studioにて、作成したプロジェクトを削除します。
作成したプロジェクトを右クリックして、[Delete Project] を選択します。

確認のウィンドウが開くので、[Delete] を選択。
プロジェクトの削除が始まります。


6.2 CloudFormationスタックの削除
プロジェクトが削除できたら、次にCloudFormationのスタックを削除していきます。
対象のスタックは2つ。ステージング環境・本番環境それぞれの推論用エンドポイントを含むスタックです。

エンドポイント・エンドポイント設定・モデルの3つのリソースがそれぞれ含まれていますね。


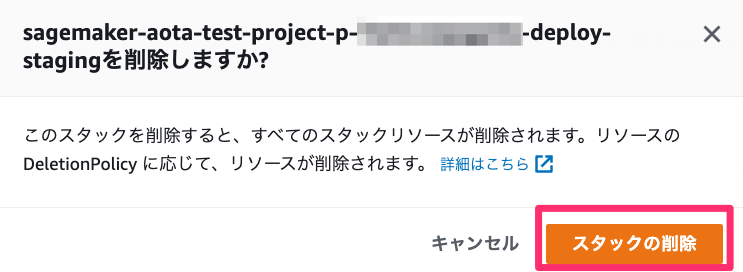
削除するスタックを左側のラジオボタンで選択して、[削除] ボタンを選択します。
すると確認のウィンドウが開くので、[スタックの削除] ボタンを選択します。

6.3 S3バケットの削除
続いて、S3バケットを削除します。
CodeCommitからクローンしてきたソースコードのフォルダ名を参照して、プロジェクトで使われていたS3バケットを特定します。
<プロジェクト名>- 以降の部分がバケット名に含まれているかと思います。

バケットが特定できたら、一旦中身を空にしてから、削除します。

6.4 CloudWatch Logsロググループの削除
次は、CloudWatch Logsのロググループを削除します。
プロジェクト名で完全一致のフィルターをかけると探しやすいです。

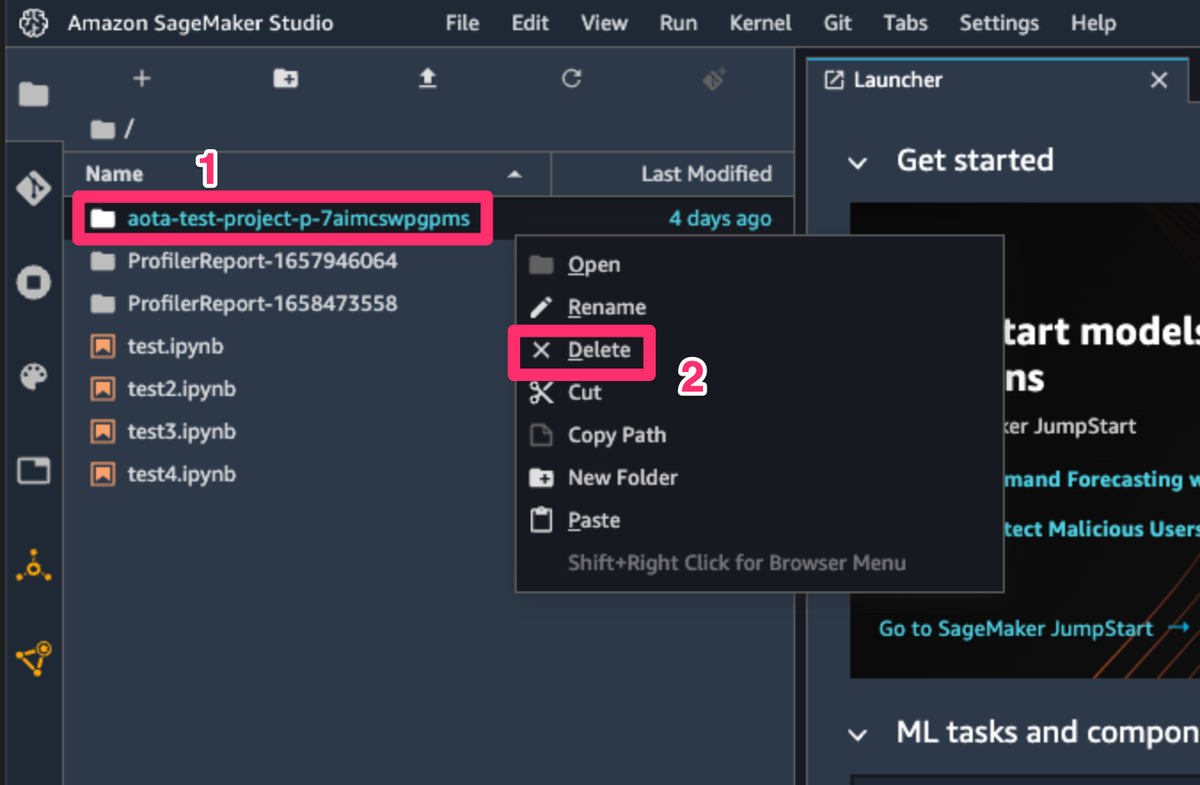
6.5 クローンしたソースコードを削除
最後に、CodeCommitからクローンしたソースコードを削除して、お片付け完了です!
おわりに
以上、今回はCodePipeline(SageMaker Project)を使用して、Model Registryに登録した学習済みモデルを継続してデプロイする仕組みを構築してみました。
ここまで、MLOps への道シリーズの記事にて、一通り継続的学習・デプロイ基盤の作成を実践できたかなと思います。
改めて作成してきた環境の構成図を見てみましょうか。

MLOpsの直接の実践部分としては、第2回と第3回(今回)で取り上げた箇所になりますね。
「できるだけシンプルに」「End To Endで」MLOpsを実践をしてみたことで、アプリやシステムにどのように機械学習を組み込んでいくのか、具体的にイメージできるようになったと感じました。
今後のデータ活用・機械学習のアーキテクチャ設計にも、しっかり生かしていきたいと思います。
この記事シリーズが、機械学習やMLOpsの第一歩を踏み出す方にとって、少しでもお役に立てていれば幸いです。
それでは、また次の記事でお会いしましょう!
参考情報リンクまとめ
MLOps への道 記事一覧
- MLOps への道① 〜Amazon SageMaker で線形回帰を行う〜
- MLOps への道② 〜SageMaker Model Building Pipelinesでモデルの学習・登録パイプラインを作る〜
- MLOps への道③ 〜CodePipelineで学習済みモデルを継続してデプロイする環境を作る〜 ←本記事です