Webバックエンド担当の湯川です。
「Webエンジニアなら知っておきたい」ということで、今回は「NoSQL」について紹介いたします。
RDBとの違いやNoSQL自体の種類、選定ポイントなどを簡単に説明したいと思います。
RDBのIndexやトランザクションあたりを把握したうえで読んでいただくと、より分かりやすいかと思います。
NoSQLってなに?
MySQLやPostgreSQLといったRDB(リレーショナルデータベース)とは異なるアプローチで、データを保存・管理するデータベースの総称です。
RDBと比べるとスケーラビリティが高いので、大量のデータを扱いたいときに使われることが多いです。
RDBとの違い
以下にざっくりとした違いをまとめました。
| 項目 | RDB | NoSQL |
|---|---|---|
| データモデル | 表形式(行と列) | 製品によって様々 |
| クエリ言語 | SQL | 製品ごとに異なる(SQLライクなものや全く異なるものもある) |
| 整合性 | ACID特性を厳密に保証 | 最終的な整合性(Eventual Consistency)を採用する場合がある |
| スケーラビリティ | 垂直スケーリング。サーバーの性能向上が主な手段。 | 水平スケーリング。サーバー台数を増やして対応。 |
| パフォーマンス | 小規模データや複雑なトランザクションで優れた性能を発揮 | 大量データの読み書きやリアルタイム処理で高いパフォーマンス |
| データ間の関係性 | リレーション(テーブル間の関係性)を明確に表現可能 | 一部(グラフ型)を除き、リレーションの機能を持っていない |
| 拡張性 | 大規模システムでの拡張は困難 | 分散型設計で拡張が容易 |
| トランザクション | 強力なトランザクション処理をサポート | トランザクション処理は限定的 |
アプリケーションを設計する観点で大きな違いは、リレーションの機能がない点と、トランザクションが限定的になっている点かと思います。
誤解を恐れずにRDBで例えると
- リレーションの機能がない: 各テーブルで外部キー制約を持てない
- トランザクションが限定的: 2テーブルに対して書き込むときに、書き込みが失敗すると片方のテーブルだけ更新される恐れがある
というイメージになるかと思います。
NoSQLの種類
データモデルによって、主に以下の4種類があります。
- キー・バリュー型
- ドキュメント型
- カラム指向型
- グラフ型
それぞれの特徴とユースケース、代表的な製品を説明します。
キー・バリュー型
「キー」と「値」がペアで保存されている、シンプルなモデルです。
値に保存できる内容は特に成約がなく、文字列、JSON、バイナリなどが保存可能です。
単純なキー検索で扱える反面、値の方を検索するのは不得意です。
キャッシュやセッションデータの保存に使われるケースが多いです。
代表的な製品:Redis、Amazon DynamoDB
ドキュメント型
JSONやXMLの形式で構造化されたデータ(ドキュメントといいます)を保存するモデルです。
JSONの形式のため、1レコード目と2レコードめで異なるカラムを持つといった、複雑な構造のデータも保存できます。
製品によっては、ドキュメントにインデックスをつけることも可能で、キー・バリューに比べると複雑な検索も可能です。
コンテンツ管理システムやログ収集などに利用されるケースが比較的多いです。
代表的な製品:MongoDB、Firebase Firestore
カラム指向型
RDBと似たような、1つの行に対して複数の列を持つモデルです。
ただ、RDBが行(レコード)単位にデータを保存することに対して、こちらは列(カラム)単位でデータを保存します。
カラムでデータを保持しているため、カラム単位での集計や分析を効率的に行えます。
逆にレコード単位での検索や更新には向いていません。
ログのような時系列データの解析、大規模データの集計が必要なときに利用されるケースが多いです。
代表的な製品:Apache Cassandra、HBase
グラフ型
「ノード」とノード間の関係性を示す「エッジ」で構成されたデータモデルです。
また、ノードには名前やメールアドレスといった「プロパティ」を保持することが可能です。
指定ノードと関係性のあるノードを検索するのが得意なのが特徴で、
SNSにおけるユーザー間のつながりや、経路探索において利用されるケースが多いです。
代表的な製品:Neo4j、Amazon Neptune
選定ポイント
RDBとNoSQLのそれぞれの種類、選定するときにどのようなポイントがあるかをまとめました。 これ以外のパターンはいくらでもありますが、一つの参考としてみていただければと思います。
- トランザクションの重要度が高い → RDB
- データ構造が固定されている → RDB
- シンプルなデータモデル → キー・バリュー型
- キャッシュなど高速なデータアクセスが必要 → キー・バリュー型
- データスキーマが頻繁に変わる → ドキュメント型
- データ構造の階層が深い → ドキュメント型
- データ分析が必要 → カラム指向型
- 複雑な関係性を表現したい → グラフ型
RDBでも実現できるけどより効率的な例の紹介
基本的に大量データを扱うときにRDBより高い効率性を持つことが特徴です。
すでにRDBで構築していても、パフォーマンスが出ないなと感じたときに導入を検討してみるというのも1つのやり方かと思います。
その中でも、グラフ型には、大量データでなくても、関係性のあるレコードを検索するという点でRDBより効率が高いという特徴があります。
例えば、ユーザーA、B、Cがいたとして、AがBを、BがCをフォローしているとします。
これをRDBで表現すると、以下のような形になるかと思います。
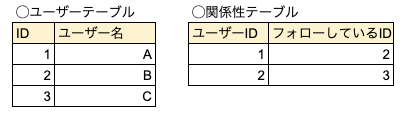
ここから、ユーザーBをフォローしているユーザー(フォロワー)のユーザー名を検索したいときは、
- ユーザーテーブルからユーザーBのユーザーIDを検索
- 関係性テーブルのフォローしているIDからユーザーBのIDを検索
- ヒットしたレコードのユーザーIDから、ユーザー名を取得
といったステップが必要になります。
※実際はテーブル結合するのでもう少しステップ数は異なりますが、何ステップか必要ということだけ認識いただければと思います。
これをグラフ型で表現すると、以下のような形になります。
(丸がノード、線がエッジを示しています)
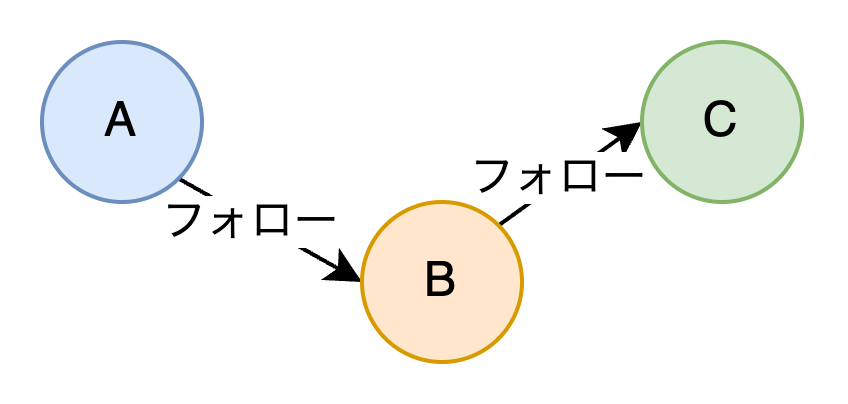
ここから、ユーザーBのフォロワーのユーザー名を検索したいときは、
「ノードBにフォローのエッジを伸ばしてきているノード」を検索できるので、
RDBより少ないステップでの検索が可能です。
これは、フォロワーのフォロワーを検索するといった様に、検索する関係性が深くなればなるほど、
検索効率に大きな差が生まれていきます。
まとめ
- NoSQLはRDB以外のDBの総称
- 大量データを扱うのが得意だが、データ自体の一貫性を保つのは不得意
- いくらか種類があるので、用途に応じて最適な製品の選択が必要
何でもNoSQLを使えば解決というわけではないので、RDBも踏まえて何を使うか考えましょう
簡単ではありますがNoSQLの紹介でした。
一度触ってみると理解が深まるかと思いますので、よろしければ各製品をインストールして使ってみてください。
次回の「Web エンジニアなら知っておきたい」シリーズもお楽しみに!