はじめに
こんにちは。クラウドネイティブ技術部の佐久間 拓志です 。
今、世界中で「生成AI」が大きな注目を集めています。ChatGPTやGoogle Gemini、Claudeといった大規模言語モデル(LLM)の登場により、私たちの業務効率は飛躍的に向上する可能性を秘めています 。
しかしLLMは、ある特定の分野の詳しい知識や、比較的新しい知識といった、学習データに含まれていない情報を扱うことが難しいという問題を抱えています。
これらの問題を解決する鍵として、RAG(Retrieval-Augmented Generation:検索拡張生成)という技術アプローチがあります 。
この記事では、RAGの仕組みの簡単な説明、RAGを利用するメリットと注意点を解説していきます。
RAGとは
RAG は、外部知識を特定のデータベースに保存し、入力文をクエリとしてデータベースを検索し、関連する知識を入力文と合わせて LLM に与えることで、外部知識に基づいた生成を行わせることを目的とした手法です。
簡単に言うと、回答を生成する前に外部情報を検索して、検索した情報に基づいた回答を生成できるということです。

RAGによる検索の流れは図1に示す通りです。
①ユーザーから質問を受け取る
②社内文書等が保管されたデータベースを検索し、質問の内容に関連した情報を取得する
③関連度の高い検索結果(上位3件など)をアプリケーションに返す
④ユーザーからの質問と、検索結果をLLMに渡す
⑤渡された情報を元にLLMが回答を返す
⑥ユーザーへ回答文を返す
このような流れで、外部のデータベースの情報を根拠として回答を生成しています。
それでは、RAGの仕組みについてもう少し詳しく解説していきます。
RAGを構成する2つの要素
RAG は、大きく分けて「レトリーバー (Retriever)」と「ジェネレーター (Generator)」の 2 つの要素で構成されています。データベースを検索し関連する情報を取得するのがレトリーバー、回答文を生成するLLMがジェネレーターと考えていただいて問題ありません。
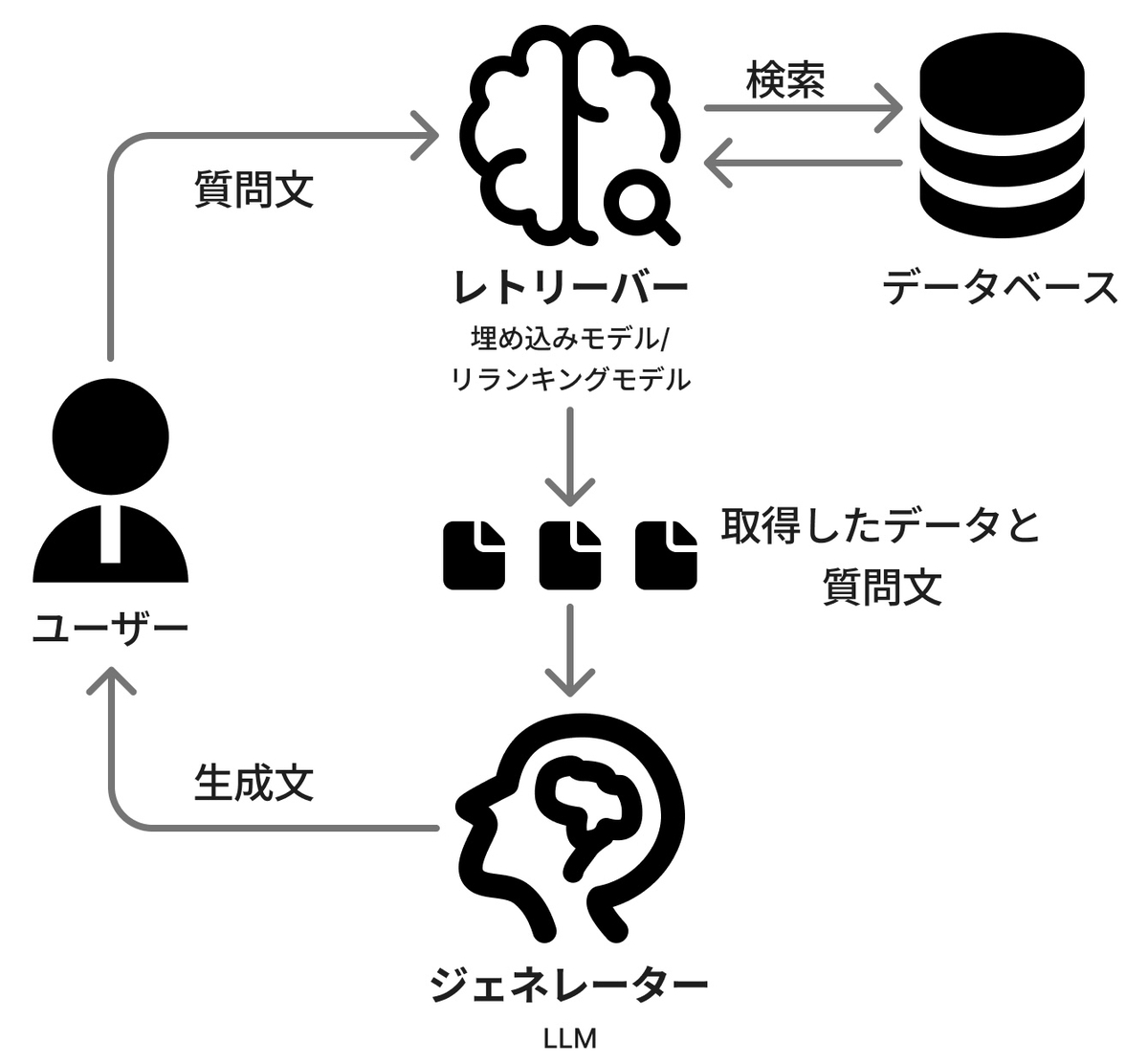
レトリーバーは、ユーザーによって入力された質問文を受け取り、その質問文に関連した文書をデータベースなどから取ってきます。その際、全ての文書をジェネレータに渡すのではなく、例えば「上位3件」などに絞って渡します。そうすることで、LLMが処理するトークンを節約できます。
ジェネレーターは、レトリーバーによって取得された文書をもとに質問文に対しての回答文を生成します。
レトリーバーには、埋め込みモデル(Embedding Model)やリランキングモデル(Reranking Model)が用いられ、ジェネレーターには、LLM が用いられます。*1
レトリーバーに用いられる埋め込みモデルとリランキングモデルはどちらも質問文と文書の類似度を算出するのに利用されます。
違いとしては、埋め込みモデルが質問文と文書情報それぞれのベクトルを用いてベクトル検索を行うのに対し、リランキングモデルは質問文と文書を結合し、より高度なアルゴリズムを用いて直接その関連性を分析します。埋め込みモデルは素早い検索を得意としており、リランキングモデルは速度は遅いが検索精度を高めることが得意です。それぞれの利点を生かすために併用されるケースが一般的です。
数万件を超えるデータの中から、埋め込みモデルで素早く広範に(例えば上位50件の)文書を絞り込み、その50件の中からリランキングモデルで最終的に上位3件に絞り込む、といった実装がしてあると思っていただけるとよいかと思います。
ベクトル検索
ベクトル検索とは、データ同士の類似性をもとに検索結果を提供する技術のことです。*2
具体的には、文章や画像などのデータをベクトルという数値表現に変換し、それらを比較して類似したものを検索します。
従来のキーワード検索は、特定の単語やフレーズなどを含むデータを見つけるのに優れていましたが、ベクトル検索はデータの意味やコンテキストをより深く理解できるため、さらに高度な検索が可能になります。

ベクトルデータベースは、高次元のベクトルデータを保存、管理、インデックス付けするものです。データポイントがベクトル(数値の配列)として保存され、類似性に基づいてクラスター化されます。
ベクトルデータベースはベクトル検索に最適化されているため、RAGでは主にベクトルデータベースを利用することが多いです。
ベクトルの比較を簡単に説明するために、質問文と文書Aおよび文書Bとの比較を例として考えていきます。
3つのデータをそれぞれベクトル化したものを簡単に表現したのが図4です。
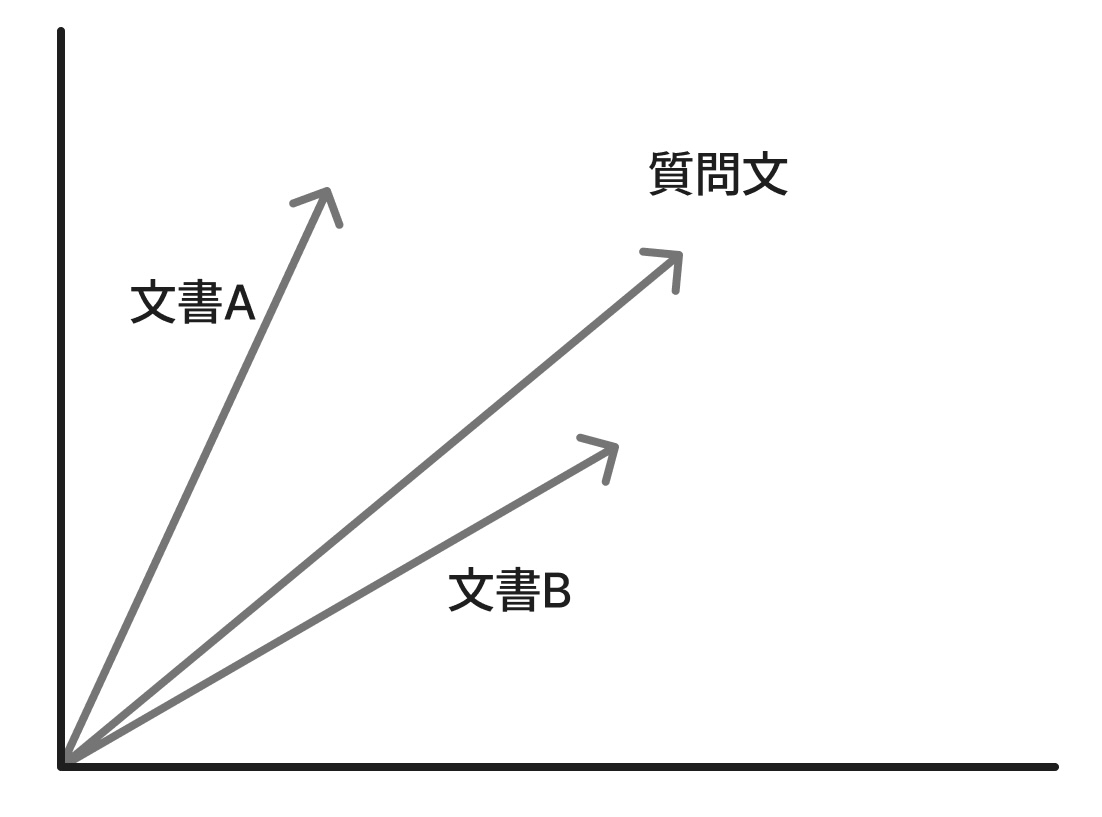
質問文のベクトルと近そうなのは文書Aと文書Bのどちらでしょうか? ベクトルの角度を見ると、質問文と文書Bとの角度が、文書Aとの角度よりも狭く見えます。 また、ベクトル同士の距離においても、文書Bの方が文書Aよりも質問文に近そうです。 このようにして、質問文により近い意味を持つ文書はどれなのかを検索するのがベクトル検索と思っていただいて問題ないと思います。
実際の類似度の算出には様々な手法がありますが、ベクトル同士の角度や距離などを用いて計算を行うことが一般的です。
チャンキング*3
RAGでは、ユーザーからの質問に関連する情報を効率的に検索しLLMに提供するために、ドキュメントを事前に小さな単位に分割(チャンキング)して保存します。この分割された個々の情報単位を「チャンク(chunk)」と呼びます。
例) 「CATFOOD」は一つの単語として見ると1チャンクですが、意味のある単語の組み合わせとして「CAT」と「FOOD」に分けると2つのチャンクになります。
チャンクは単一の文や段落、あるいはそれ以上の規模を持つデータ片として定義されます。これにより、モデルや検索エンジンが個別のデータ部分を評価し、最適な関連性を見つけ出せるようになります。
チャンクの役割は、単にデータを小さくすることだけではありません。重要なのは、分割後のデータが元の意味や文脈を維持することです。単語の羅列ではなく、ある程度の意味を持つ文やフレーズを単位とすることでデータの分断による情報喪失を防ぎつつ、効率的な処理を可能にします。
RAGにおけるチャンキングの利点は以下の通りです。
検索精度の向上
チャンキングによって情報が適切な単位で整理されると、検索対象が小さくなる。それによってモデルは関連性の高い情報にアクセスしやすくなる。データ処理の効率化
チャンキングによって膨大な文書情報を分割することで、モデルがデータ全体を無駄なく活用できるようになる。それによって処理時間の短縮と計算リソースの最適化が実現できるLLMのコンテキストウィンドウ制限への対応
大量のテキストを適切なサイズのチャンクに分割することで、例えば100ページ以上に及ぶ取扱説明書の該当する部分だけをLLMへ渡すことができる。
それによってLLMのコンテキストウィンドウに収まるようにする。
チャンキングされたデータを、埋め込みモデルやリランキングモデルを用いて検索し、最適な結果を得る。
そのような仕組みで、RAGという技術は実現されています。
RAGを採用するメリット
仕組みが分かったところで、RAGを採用するメリットについて見ていきます。
メリットは大きく分けて以下の2点です。*4
- 最新性
- 検証可能性
それぞれについて詳しく説明していきます。
最新性
LLMの最大の弱点の一つは、その知識が「学習した時点」で凍結されていることです。例えば、2023年までのデータで学習したモデルに「今日の株価は?」と聞いても正しい回答は返ってきません。
RAGはモデル本体の知識に頼るのではなく、回答のたびに都度検索を行い、最新のドキュメントやデータベースから情報を持ち込みます。
これにより、AIは「昨日リリースされたばかりの社内製品の新機能」や「今朝更新された社内通達」についても、データベースに情報を追加したものについては正確に参照して回答することが可能になります。
検証可能性
LLMは事実に基づかない情報(ハルシネーション)を生成することがあります。これは、AIが「それらしい答え」を統計的に予測して文章を作っているだけで、その内容が「事実かどうか」を本質的には理解していないために起こります。
RAGは、LLMに「渡された根拠の範囲内だけで答えなさい」と強く制約をかけることができます。これによりハルシネーションを大幅に抑制することができます。
また、RAGは「どの文書のどの部分を根拠にして、この回答を作ったか」という参照ドキュメントを一緒に提示するような実装が非常に容易です。AIの回答が怪しいと思ったら、すぐに元の出典リンクをクリックして裏取りをすることができるのは大きなメリットです。
RAGを利用する上での注意点
RAGを利用する際に注意しなければならない点があります。 それは、回答品質が「検索性能」に依存する点です。
どういうことかというと、「検索が当たらなければ、生成も当たらない」ということです。
LLMがどれほど優秀でも、検索で的外れな情報や、古くて役に立たない情報ばかりを拾ってきたら、それに基づいた回答も当然ながら的外れなものになります。
特に以下の2点が、回答品質に致命的な影響を与えます。
データベースの品質の悪さ
そもそもデータベースに保存されているドキュメントの質が悪ければ、回答精度も悪くなる。チャンクの切り方の悪さ
チャンクサイズが大きすぎると、LLMが情報を読み取りきれず、重要な情報を見落としてしまう可能性がある。
逆にチャンクサイズが小さすぎると、情報が断片的になりすぎてしまい、文脈が途切れてしまう。その結果、LLMが質問の意図や背景を正確に理解できず、適切な回答を生成できなくなる可能性がある。
検索精度が低いとRAGそのものの価値が薄れてしまう点に注意してください。
まとめ
本記事ではRAGについて、その仕組みから利点、そして注意点を解説しました。
RAGは、「回答を生成する前に、まず外部を調べる」という、私たち人間が知的作業を行う際にごく自然に行っているプロセスを、AIのアーキテクチャに持ち込むものです。
今まで、「生成AIは嘘をつくから業務に使いづらい」、「AIは最新情報を知らないじゃないか」などの理由から生成AIに手を出しづらかった方もいるかもしれません。
RAGはそんな悩みを解決する一つの手段になると思います。
活用する上での注意点はあるものの、業務の効率化における強力な手段の一つとして頭の片隅に置いておいていただけると嬉しく思います。
この記事をきっかけに、生成AIの活用幅が広がる一助となれば幸いです。
参考文献
*1:リランキングモデルによる RAG の日本語検索精度の向上
https://developer.nvidia.com/ja-jp/blog/rag-with-sota-reranking-model-in-japanese/
*2:ベクトル検索とは| IBM
https://www.ibm.com/jp-ja/think/topics/vector-search
*3:RAGソリューションの開発 - チャンキング フェーズ -
https://learn.microsoft.com/ja-jp/azure/architecture/ai-ml/guide/rag/rag-chunking-phase
*4:What is retrieval augmented generation (RAG)?
https://www.ibm.com/think/topics/retrieval-augmented-generation